Temporal Workflow Best Practices: Achieving 99.99% Reliability with High-Availability



TL;DR for CTOs and VP Engs: A single regional outage can take down every workflow Temporal is orchestrating payments, bookings, AI agents, everything. Temporal Cloud HA extends your SLA from 99.9% to 99.99% and automates failover in under 20 minutes. But enabling HA without reviewing your workflow design first can amplify existing reliability problems instead of solving them. This guide covers what HA gives you, what it costs, and the design decisions that determine whether it protects you or exposes you.
A payment flow is mid-flight auth captured, ledger update in progress when the cloud region goes down. With a standard single-region setup, that workflow is gone. Retries storm in, the ledger is inconsistent, and your on-call engineer spends the next three hours manually reconciling transactions. This is the scenario Temporal Cloud High-Availability (HA) was built to prevent.
Temporal Cloud High-Availability (HA) was built to prevent exactly this scenario. But HA is not a setting you flip on and walk away from. As Temporal consultants who have worked through these failure modes in production across fintech, healthcare, and AI agent workloads, Xgrid’s Temporal expert engineering team has seen what happens when teams enable HA before reviewing the fundamentals. This guide is a review covering Temporal workflow best practices for HA configuration, idempotency design, and production observability.
Core Capabilities and Business Benefits
The transition to HA introduces several key features that translate technical mechanics into operational peace of mind:
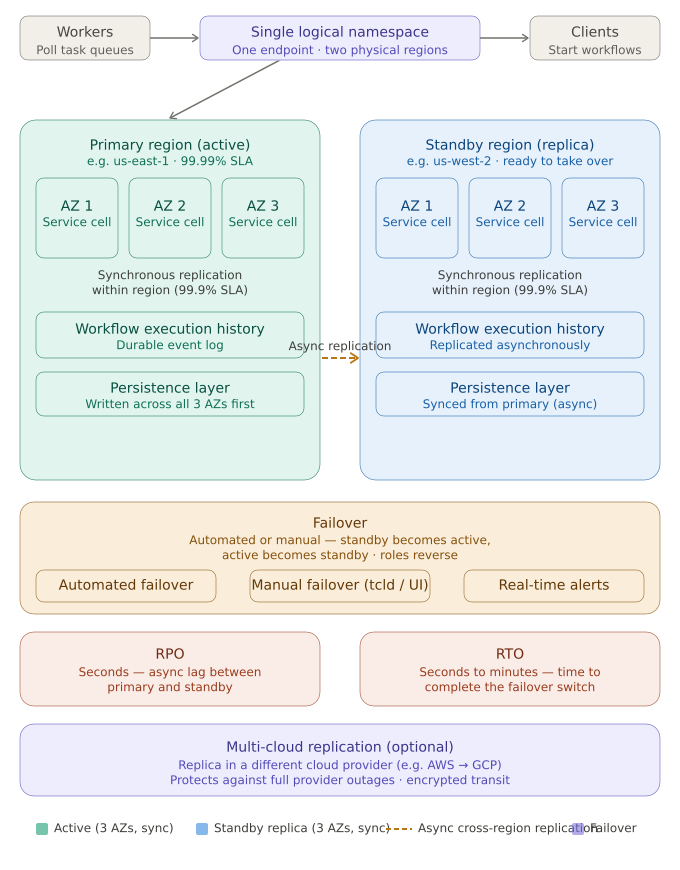
- Asynchronous Cross-Region Replication: Continuous data copying between a primary and replica namespace ensures that your workflow history is always safe.
- Automated Failover: Health-check-driven triggers minimize manual intervention, switching traffic to a healthy replica in minutes.
- Transparent DNS Switchover: With a 15-second TTL, clients automatically reconnect to the active region without complex reconfiguration.
- Conflict Resolution: After failover, Temporal reconciles divergent workflow progress, maintaining at-least-once execution semantics.
Why standard Temporal resilience isn’t enough for high-value workflows
Standard Temporal Cloud namespaces already offer solid protection three Availability Zones, zero RPO for single-AZ failures, 99.9% SLA. For many workloads, that’s sufficient.
But for teams running payment orchestration, multi-step business processes, or long-running AI agent pipelines, the risk profile is different. A regional outage, not just a single AZ can take down your entire Temporal cluster. And when your Temporal namespace is the brain coordinating money movement, booking confirmations, or agentic tool calls, “down for 8+ hours” is not an acceptable outcome.
What this means for your business:
- At 99.9% SLA, you have ~8.7 hours of allowable downtime per year
- At 99.99% (HA), that drops to under 53 minutes roughly 10x less
- For a payment system processing $1M/day, even one hour of regional downtime has a direct revenue cost that dwarfs the 2x consumption multiplier HA adds
Temporal Cloud HA extends protection across separate isolation domains: different regions within the same cloud, or entirely different cloud providers (AWS and GCP). It’s the difference between surviving an AZ hiccup and surviving a full regional disaster.
When does Temporal HA make sense for payment orchestration?
Temporal HA makes sense for payment orchestration when the cost of a double-execution, a duplicate charge, a duplicate refund, or an inconsistent ledger exceeds the cost of the 2x HA pricing multiplier. The prerequisite is that every payment activity is idempotent before HA is enabled.
Here is what Xgrid has seen across the Temporal ecosystem in production environments: A fintech client running payment authorization and capture flows had enabled HA on their Temporal namespace, validated failover in staging, and considered it production-ready. Shortly after, a real regional failover exposed a double-charge issue: the capture activity wasn’t idempotent, so the replica’s retry triggered a second charge at the payment gateway. The problem was eventually discovered through customer complaints rather than monitoring.
Temporal Cloud HA uses at-least-once execution semantics during failover. Some activities will execute more than once. For payment workflow reliability, this is a critical design constraint that must be addressed before enabling HA.
| Payment scenario | Risk without idempotency design |
|---|---|
| Auth/capture in flight during failover | Double-charge if capture activity retries on replica |
| Ledger update mid-saga | Inconsistent balances if compensating transaction also replays |
| Refund or chargeback flow | Duplicate refund issued to customer |
| Fraud check with external API | Duplicate API calls producing inconsistent fraud scores |
Temporal workflow best practices for fintech payment orchestration:
- Assign a stable, client-generated idempotency key to every payment activity before the activity executes not inside it
- Use Temporal’s saga pattern with explicit compensation logic for multi-step flows (auth → capture → ledger update)
- Set bounded retry policies on capture and ledger activities unbounded retries on a non-idempotent activity is a double-charge waiting to happen
- Validate that your payment gateway, ledger, and fraud service all accept and honour idempotency keys end-to-end, not just at the Temporal layer
- Test failover in a staging environment with production-representative transaction volumes before enabling HA on the live namespace
How should AI agent teams design for Temporal failover?
AI agent orchestration on Temporal requires the same idempotency discipline as payment flows, but the failure modes are harder to detect because side effects are more distributed and less auditable.
Temporal for AI agent orchestration is one of the fastest-growing use cases Xgrid sees in production. The challenge with durable AI agents is that at-least-once execution does not just mean a duplicate charge, it means a second email sent by an outreach agent, a duplicate write to an external database, a human-in-the-loop approval request that fires twice and confuses the reviewer, or inconsistent state between a long-running research agent and its downstream consumers. These side effects are harder to roll back than a financial transaction and often harder to detect because AI agent workflows have more branching and more external surface area.
Temporal workflow best practices for AI agent orchestration:
- Treat every tool call, web search, code execution, API call, database write as a side-effectful Temporal activity and design it as idempotent
- Use Temporal signals for human-in-the-loop approvals so approval requests survive failover without double-firing
- Build Temporal workflow observability into the agent workflow from the start replication lag metrics alone will not surface a wrong branch taken post-failover
- Checkpoint long-running agent state explicitly using Temporal activities rather than relying solely on Temporal workflow history replay for workflows that run for hours or days
- Log the idempotency key and execution attempt count in every tool call activity so duplicate executions are auditable after the fact
If your AI agents are currently orchestrated with ad-hoc scripts, callbacks, or lightweight task queues, Temporal gives you durable execution, structured retries, and workflow state visibility. The idempotency design work is the prerequisite, not the follow-on.
What are the Temporal Cloud HA replication modes and when should you use each?
Temporal Cloud HA offers three replication modes: same-region (cross-cell, currently in preview), multi-region (same cloud provider), and multi-cloud (AWS and GCP). Each targets a different failure domain.
| Mode | Replication Scope | Use Case | RPO/RTO Goals |
| Same-region (preview) | Same region, different cell/AZ (AZ-level) | Protect against cell (hardware/software) failures. Low-latency (very short distance). | 1m RPO, 20m RTO (cell outage) |
| Multi-region | Different regions (same cloud) | Survive a full region outage (e.g. AZ/DC loss). | 1m RPO, 20m RTO (regional outage) |
| Multi-cloud | Different providers (AWS ↔ GCP) | Survive a cloud-wide outage. | 1m RPO, 20m RTO (cloud outage) |
| Standard (no HA) | Single region (3 AZs) | Standard availability (99.9% SLA). | Zero RPO, ~0 RTO (single-AZ outage) |
Selection guidance:
- Same-region mode is in preview as of this writing validate GA status with Temporal directly before building a production dependency on it
- Multi-region is the standard starting point for teams with an existing AWS or GCP footprint and straightforward disaster recovery requirements
- Multi-cloud is the right choice when the requirement is survival of a cloud-provider-wide incident it requires operational readiness to manage cross-cloud networking and is a more complex configuration
All three HA modes share the same RPO/RTO targets: sub-1-minute Recovery Point Objective and 20-minute Recovery Time Objective. Temporal attempts a graceful handover first, draining in-flight tasks before forcing a switch if the primary is unresponsive.
Enabling Temporal HA in ProductionTemporal Cloud HA can improve regional resilience, but only if your workflows are ready for at-least-once execution, retry storms, replication lag, and controlled failover. Use Xgrid’s Temporal Production Deployment Checklist to validate idempotency, retry limits, worker scaling, observability, versioning, security, and runbooks before choosing standard Temporal Cloud, multi-region HA, or multi-cloud HA. |
What does Temporal Cloud HA cost and how do you evaluate the trade-off?
Temporal Cloud’s HA pricing follows the same consumption-based model as everything else on the platform: no flat fee, no separate license. The rule is simple: apply a 2x multiplier to the Actions and Storage in the namespace you are replicating. Every write is committed to both your primary and replica, so you pay for both.
The business case is straightforward. Moving from the standard 99.9% SLA to the 99.99% HA SLA means going from ~8.7 hours of allowable downtime per year to under 53 minutes. For a payment system processing $1M/day, even one hour of regional downtime has a direct revenue cost that dwarfs a 2x consumption multiplier.
The more important question that teams often skip is whether their workload is ready for HA. Enabling replication on a namespace where activities aren’t idempotent, or where the workflow retry logic hasn’t been reviewed, can amplify existing problems rather than protect against them. The cost of HA is predictable. The cost of a poorly designed HA failover is not.
Not sure if your Temporal setup is HA-ready? Not sure if your Temporal setup is HA-ready? Xgrid’s Temporal expert engineering team works with you to review your architecture, failure modes, and observability before you go live.
How do you monitor Temporal HA replication health in production?
Temporal HA replication health is monitored through replication lag metrics (P50, P95, P99) exposed by Temporal Cloud. A 60-second alert threshold on lag is the recommended starting point for production namespaces.
Temporal provides real-time replication lag metrics at P50, P95, and P99 percentiles. These metrics measure the delay between a write on the primary namespace and its commit on the replica. Alert thresholds on these metrics ensure synchronisation issues surface before they affect a failover event. Replication lag metrics are available in the Temporal Cloud UI and via the metrics endpoint for integration with your existing observability stack.
Common mistakes teams make when enabling Temporal HA
These are the six most frequent Temporal production deployment mistakes Xgrid sees when teams enable HA without a structured readiness review.
- Enabling HA before auditing activity idempotency The most common and most expensive mistake. Teams enable replication and assume Temporal handles the rest. At-least-once execution semantics means any non-idempotent activity: a payment capture, an email send, an API write will cause a real side effect on replay. Audit every activity that touches an external system before enabling HA.
- Testing failover only in staging with synthetic workloads Staging failover tests with low transaction volumes mask retry storms that appear at production scale. Run failover tests with production-representative Temporal task queue backlogs and concurrent workflow counts.
- Not setting a replication lag alert Replication lag is the leading indicator of a degraded failover. Teams that skip this alert discover lag issues during an actual regional outage, not before.
- Treating HA as a replacement for Temporal workflow versioning discipline HA protects against infrastructure failure. Temporal workflow versioning protects against code deployment breaking in-flight executions. These are separate concerns. Teams that conflate them end up with HA-protected namespaces that still break on deployment.
- Not building a manual failover runbook Temporal HA supports manual failover trigger option via UI and CLI for teams that want to initiate a controlled switch before automated health checks fire. Teams that skip the runbook during setup face a documentation search during an active incident.
- Skipping the same-region preview status check Same-region HA mode is currently in preview. Teams that build a production DR strategy around a preview feature without checking GA status with Temporal risk a support gap.
Production Readiness Checklist for Temporal Cloud HA
Before enabling Temporal Cloud HA for mission-critical workflows, confirm:
- Every activity that touches an external system is idempotent
- Payment, ledger, email, API, and database calls use stable idempotency keys
- Idempotency keys are generated before the activity executes, not inside the activity
- Retry policies have bounded attempts, exponential backoff, and clear timeout limits
- Capture, refund, ledger, and fraud-check activities have been tested for duplicate execution
Frequently asked questions about Temporal workflow high-availability
What is Temporal Cloud High-Availability and how does it work? Temporal Cloud HA is a multi-region and multi-cloud replication feature that extends Temporal’s standard 99.9% SLA to 99.99%. It works by continuously replicating workflow history and namespace state from a primary region to one or more replica regions. When a regional outage is detected, health-check-driven automation initiates failover to the replica, and DNS TTL (set to 15 seconds) ensures clients reconnect to the active region without manual reconfiguration.
What is the RPO and RTO for Temporal Cloud HA? Temporal Cloud HA targets a sub-1-minute Recovery Point Objective (RPO) and a 20-minute Recovery Time Objective (RTO). RPO defines the maximum data loss window the gap between the last replicated write and the point of failure. RTO defines the time to restore service on the replica. Temporal attempts a graceful handover first, draining in-flight tasks, before forcing a switch if the primary is unresponsive.
Do Temporal activities run twice during a failover? Yes. Temporal Cloud HA uses at-least-once execution semantics. During a failover, some activities that were in-flight on the primary will be retried on the replica. This is expected behaviour, not a bug. The correct response is to design every activity that touches an external system payment gateways, email services, databases, external APIs as idempotent so that running it twice produces the same result as running it once.
How do I make a Temporal activity idempotent? A Temporal activity is idempotent when running it multiple times with the same input produces the same result and the same side effects as running it once. In practice, this means generating a stable idempotency key before the activity executes (not inside it), passing that key to the external system, and ensuring the external system honours it. For payment gateways, use the gateway’s native idempotency key header. For database writes, use upsert semantics or check-then-write patterns with the idempotency key as the unique constraint.
What is the difference between Temporal multi-region and multi-cloud HA? Multi-region HA replicates between two regions on the same cloud provider (for example, AWS us-east-1 and AWS us-west-2). It protects against a full regional outage within one provider. Multi-cloud HA replicates between AWS and GCP and protects against a cloud-provider-wide outage. Multi-cloud requires more complex cross-cloud networking configuration and is appropriate for workloads where provider-level resilience is a compliance or business requirement.
How much does Temporal Cloud HA cost? Temporal Cloud HA applies a 2x multiplier to Actions and Storage on the replicated namespace. There is no flat fee or separate licence. The multiplier applies because every write is committed to both the primary and the replica. There is no additional charge for failover events or the number of replicas beyond the Actions and Storage consumed.
When should I use Temporal HA versus standard Temporal Cloud? Use Temporal HA when the cost of a regional outage revenue loss, incident response, customer impact, regulatory exposure exceeds the cost of the 2x Actions and Storage multiplier. For payment orchestration, AI agent pipelines, and business process workflows where Temporal is the central coordination layer, HA is typically justified. For development namespaces, low-stakes background jobs, or workloads where an 8-hour outage window is acceptable, standard Temporal Cloud is sufficient.
Can I enable HA on an existing Temporal namespace? Yes. Temporal Cloud HA can be applied to existing namespaces, not just new ones. The configuration process is the same whether you are retrofitting an existing namespace or starting fresh. The prerequisite is not a namespace migration, it is the idempotency and retry logic review of your existing workflows before replication is enabled.
Should I hire a Temporal consultant to enable HA? Yes. teams that engage a certified Temporal partner before enabling HA avoid the most expensive mistakes: non-idempotent activities causing double-charges, inadequate replication lag monitoring, and missing failover runbooks. Xgrid’s forward-deployed engineers have resolved these patterns across multiple production deployments.
Conclusion: HA is a capability, not a guarantee
Temporal Cloud HA removes single-region dependency and delivers a 99.99% SLA. That is a meaningful step forward for any team running mission-critical workflows, fintech payment orchestration, multi-step business processes, or agentic AI pipelines where reliability directly affects customer outcomes.
But HA is a capability, not a guarantee. Teams that get the most out of it are the ones that have already reviewed their workflow patterns, hardened their activity idempotency, and established clear observability and ownership before the first failover event.
That review is exactly what Xgrid provides. Whether you’re evaluating Temporal for the first time or already running workflows in production, our Temporal engineering team has seen how these failure modes play out and how to design around them.
Related Temporal Production Guides
- For retry behavior and outage cost control, read: Temporal Retry Policies at Scale: How Unbounded Retries Drive Costs
- For observability, stuck workflows, Search Attributes, and production monitoring, read: Temporal Observability in Production Guide
- For long-running workflow failure modes, heartbeats, history growth, and Continue-As-New, read: Long-Running Temporal Workflows in Production
- For AI agent orchestration risks during retries and failover, read: Temporal AI Agent Orchestration: 11 Production Failure Patterns
Related Articles



Related Articles
Established in 2012, Xgrid has a history of delivering a wide range of intelligent and secure cloud infrastructure, user interface and user experience solutions. Our strength lies in our team and its ability to deliver end-to-end solutions using cutting edge technologies.
NAVIGATE
Cloud & DevOps Web & Mobile Apps Temporal Digital Marketing GTM Engineering Marketo Consulting HubSpot Consulting Company Careers ResourcesOFFICE ADDRESS
US Address:
Plug and Play Tech Center, 440 N Wolfe Rd, Sunnyvale, CA 94085
Dubai Address:
Dubai Silicon Oasis, DDP, Building A1, Dubai, United Arab Emirates
Pakistan Address:
Xgrid Solutions (Private) Limited, Bldg 96, GCC-11, Civic Center, Gulberg Greens, Islamabad
Xgrid Solutions (Pvt) Ltd, Daftarkhwan (One), Building #254/1, Sector G, Phase 5, DHA, Lahore
Xgrid © 2026. All rights reserved.