Temporal Retry Policies at Scale: How Unbounded Retries Become a Cost Problem During Outages



Why the retry policy you set on day one looks fine in staging, behaves fine at low volume, and becomes a billing emergency the moment a dependency goes down at scale
| TL;DR
Temporal’s default retry policy — unlimited retries, 1-second initial interval, 2x backoff coefficient, 100-second maximum interval — is reasonable for a single workflow. At production scale with hundreds or thousands of concurrent workflows, it becomes a cost multiplier during dependency outages. Every retry generates billable actions. When a connector goes down and every in-flight workflow begins retrying simultaneously, the action count for that hour can exceed your entire normal-day budget. This post explains exactly why this happens, what the four retry strategies are that fix it, and the specific configuration levers that matter most. |
Why Retry Policy Is a Billing Problem, Not Just a Reliability Problem
Most engineers think about retry policy in terms of reliability: how many times should Temporal try before giving up, and how long should it wait between attempts? These are the right questions for correctness. They are incomplete questions for cost.
In Temporal, every retry attempt generates billable actions. An activity that is scheduled, starts, and fails produces three actions. If that activity is retried three times before succeeding, the total is nine actions — three times the happy-path cost. If it is retried ten times, the total is thirty actions for a single activity execution.
At low workflow volume, this math is invisible. At production scale — where hundreds or thousands of workflows are concurrently executing activities against the same downstream dependency — a dependency outage causes every one of those activities to begin retrying simultaneously. The billable action count during the outage hour is a direct function of the retry policy: specifically, how many retry attempts fit inside the outage window, multiplied by the number of concurrent workflows affected.
The Scale MultiplierA retry policy that generates 10 retry attempts per hour of outage costs 30 extra actions per workflow. With 500 concurrent workflows, that is 15,000 extra actions per hour of downtime — on top of normal usage. With 2,000 concurrent workflows, it is 60,000 extra actions per hour. The retry policy that looked benign in staging becomes the primary billing driver during every production incident involving a dependency. |
How Actions Accumulate: The Retry Math
Before looking at the strategies that fix this, it helps to be precise about how actions accumulate per retry cycle. This is not a theoretical concern — it is the mechanism that connects retry policy configuration directly to billing outcomes.
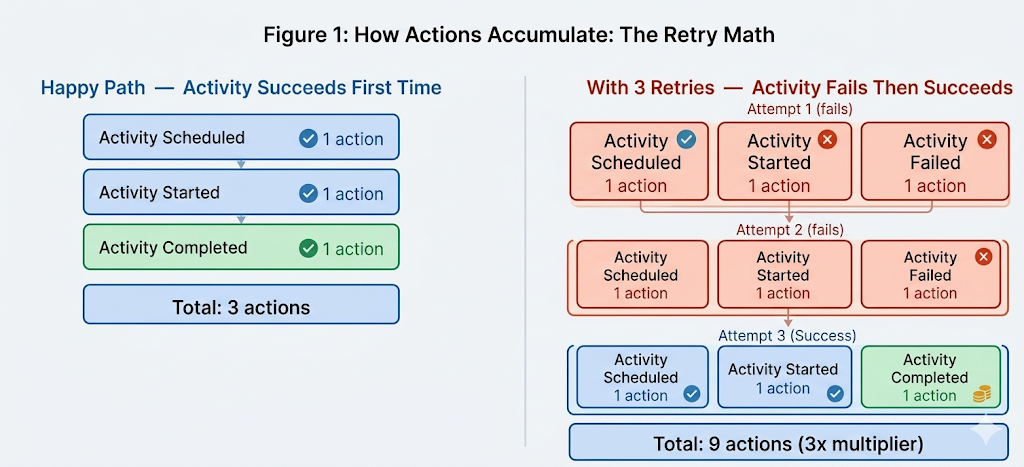
Figure 1: Happy path vs three retries for a single activity. Three retries triple the action count from 3 to 9. At production scale, this multiplier applies to every concurrent workflow hitting the same failing dependency simultaneously.
The action math is straightforward: each retry cycle adds three actions — activity scheduled, activity started, activity failed. A workflow that ultimately succeeds on the fourth attempt has generated twelve actions for a single activity that the happy path would have completed in three. The cost of a retry policy is therefore determined by two variables: how many retry attempts occur during a given outage window, and how many concurrent workflows are affected.
The backoff coefficient controls the first variable directly. It determines how quickly the interval between retry attempts grows. A coefficient of 2 doubles the wait time between each attempt. A coefficient of 4 quadruples it. The higher the coefficient, the fewer retry attempts fit inside any given outage window — which means fewer actions, lower cost, and less pressure on the recovering dependency.
What the Backoff Coefficient Actually Controls
The backoff coefficient is the most impactful single configuration change for reducing retry-related cost during outages. It is also the most commonly left at its default value of 2.
The effect of the coefficient is best understood by comparing retry timelines rather than individual intervals. With a coefficient of 2 and a 100-second maximum interval — Temporal’s defaults — a one-hour outage generates approximately 10 to 12 retry attempts per workflow. With a coefficient of 4 and a maximum interval of 5 minutes, the same outage generates approximately 4 to 5 retry attempts. That is a 60 to 70 percent reduction in retry-generated actions for the same outage duration, with no change to the underlying reliability behaviour.
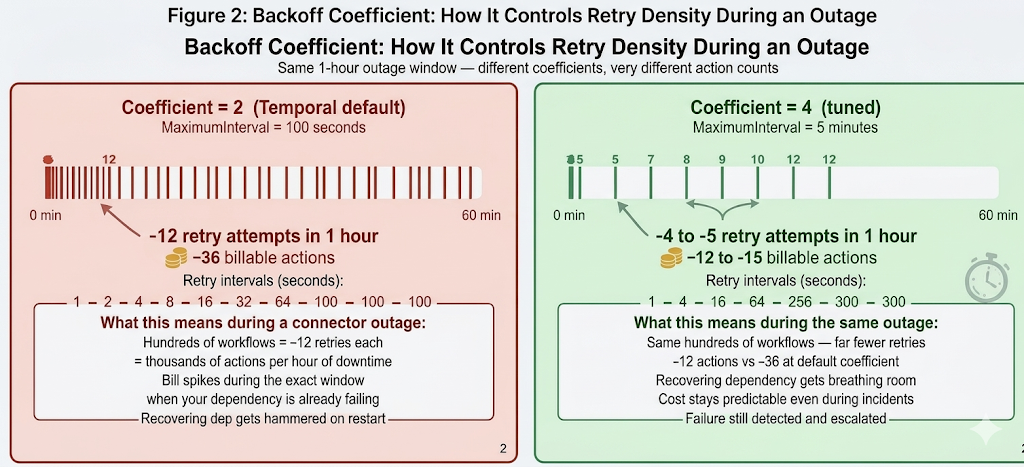
Figure 2: One-hour outage with coefficient 2 (default) vs coefficient 4 (tuned). Each vertical tick mark represents a retry attempt. The default policy fits roughly 3 times as many retries into the same window. At production scale, that difference translates directly into action cost and into the load hitting the recovering dependency.
The tick marks in Figure 2 represent individual retry attempts. With the default coefficient, attempts cluster densely in the early part of the outage and then space out to one per 100 seconds. With a higher coefficient, the spacing grows quickly — which means fewer total attempts during a long outage and a recovering dependency that gets significantly less simultaneous traffic when it comes back online.
Changing the backoff coefficient does not reduce reliability. The workflow still retries. It just retries less frequently, which is the correct behaviour when a dependency is experiencing a sustained outage rather than a transient blip. Quick retries are useful for transient errors lasting seconds. For outages lasting minutes or hours, a high retry frequency serves no purpose and incurs significant cost.
The Recovering Dependency ProblemA frequently overlooked consequence of the default retry policy: when a dependency recovers from an outage, every workflow that was waiting on it fires its next retry simultaneously. If 500 workflows are waiting and each fires within seconds of the dependency recovering, the recovered service receives a burst of 500 simultaneous requests — which can immediately crash it again. A higher backoff coefficient with a longer maximum interval naturally staggers these requests, giving the recovering service breathing room to stabilize before being hit with full load. |
The Four Retry Strategies
Adjusting the backoff coefficient is one lever. There are three others, and the right combination depends on the specific failure characteristics of the activity being configured. These four strategies are not mutually exclusive — most production-grade retry policies combine elements of several.
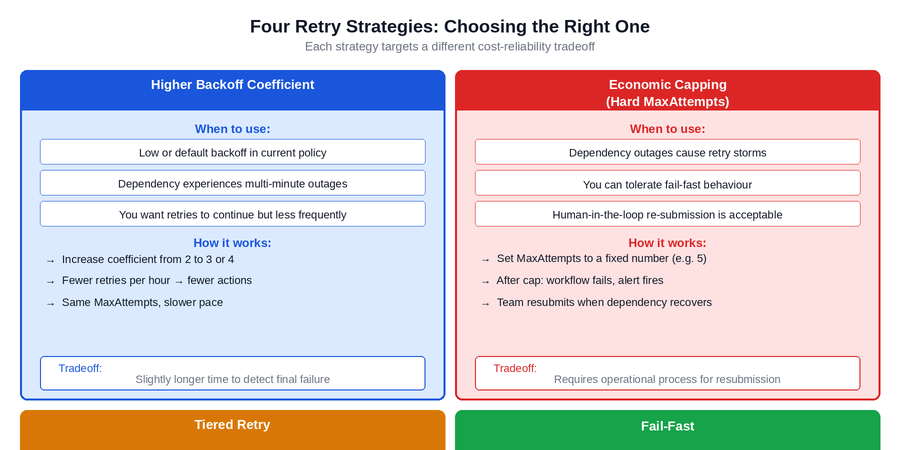
Figure 3: The four retry strategies and their appropriate use cases. Each addresses a different cost-reliability tradeoff. The correct choice depends on the failure characteristics of the specific dependency and the operational process available for handling escalated failures.
Strategy 1: Higher Backoff Coefficient
The lowest-effort change with the highest immediate impact on retry-related cost. Increasing the coefficient from 2 to 3 or 4 on activities that call unreliable or occasionally unavailable dependencies reduces retry density during outages without requiring any changes to MaxAttempts or operational process. This is the right starting point for most teams.
Strategy 2: Economic Capping with Hard MaxAttempts
Setting a hard ceiling on total retry attempts — for example, MaxAttempts of 5 — makes cost predictable regardless of outage duration. After the cap is reached, the activity fails, the workflow fails or escalates, and an alert fires. This requires an operational process: someone or something must resubmit the failed workflows when the dependency recovers. Teams that have that process in place find that fail-fast combined with resubmission is both cheaper and operationally cleaner than indefinite retrying.
Strategy 3: Tiered Retry
Quick retries for transient errors — the kind that resolve in seconds — combined with slow retries for sustained outages. The implementation involves setting a low MaximumInterval for the first few attempts and a much higher one for subsequent attempts, or using custom workflow logic to detect extended outage conditions and switch to a longer wait. This strategy preserves fast recovery for the common case while limiting cost during the rare but expensive extended outage case.
Strategy 4: Fail-Fast
For operations where a fresh workflow run is preferable to a long-running retry loop — scheduled jobs, idempotent data sync operations, batch processing — retrying for a short window and then failing cleanly is often the correct design. The workflow fails, the scheduler or event trigger creates a new run when conditions are right, and the state of the system is always clear. This avoids the hidden complexity of long-running retry loops and makes outage behaviour predictable and auditable.
Are Your Temporal Retry Policies Production-Ready?Temporal retries protect reliability, but at scale they also affect cost, dependency recovery, incident behavior, and operational load. A retry policy that looks harmless in staging can become expensive when hundreds or thousands of workflows hit the same failing service. Xgrid’s Temporal Production Deployment Checklist helps teams validate retry calibration, idempotency, timeouts, worker scaling, observability, versioning, and failure handling before production outages create billing spikes. |
NonRetryableErrorTypes: The Most Overlooked Configuration Field
The four strategies above address retries of transient failures — situations where retrying may eventually succeed. There is a separate, equally important problem: retrying errors that will never succeed.
Without NonRetryableErrorTypes configured, Temporal retries every error type — including business validation errors that are deterministically wrong. An invalid input will be invalid on every retry. An entity that does not exist will not exist on retry. An account with insufficient funds will not gain funds between retry attempts. Every one of these retries generates billable actions and delays the failure signal to the engineering team.

Figure 4: Retryable vs non-retryable error types. The left column represents errors where retrying may succeed. The right column represents business errors where retrying will always fail. Without NonRetryableErrorTypes set, Temporal retries the entire right column up to MaxAttempts, generating wasted actions on every attempt.
The fix is explicit classification. For every activity, the team that owns it is best positioned to know which error types represent transient failures and which represent deterministic business failures. That classification belongs in NonRetryableErrorTypes, set at the activity level. It is a small amount of code that eliminates an entire category of wasted action spend.
In practice, this classification is also a forcing function for better error design. Activities that currently return generic error types — or that bubble up third-party errors without wrapping them — need to be refactored to return typed errors before NonRetryableErrorTypes can be configured effectively. This refactoring is worth doing independently of the retry policy work because it also improves debuggability and makes incident response faster.
How to Identify Missing NonRetryableErrorTypesLook at your failed workflow histories in the Temporal UI. If you see the same activity failing with the same error type multiple times before ultimately failing permanently, that error type is a NonRetryableErrorTypes candidate. Any error whose message indicates a business validation failure — not found, already exists, invalid input, permission denied — should be classified as non-retryable. |
What This Looks Like in a Real Production System
The patterns described above are not theoretical. They are what production audits of Temporal environments consistently surface when average actions per workflow execution are significantly higher than the happy-path action count would predict.
The diagnostic signal is simple: if a workflow type’s average actions per run is substantially higher than its happy-path baseline, the difference is retries. A workflow with a happy path of 8 actions showing an average of 156 actions per run is generating approximately 148 actions from retries alone. That is the signature of a workflow that regularly encounters dependency downtime and retries against it indefinitely.
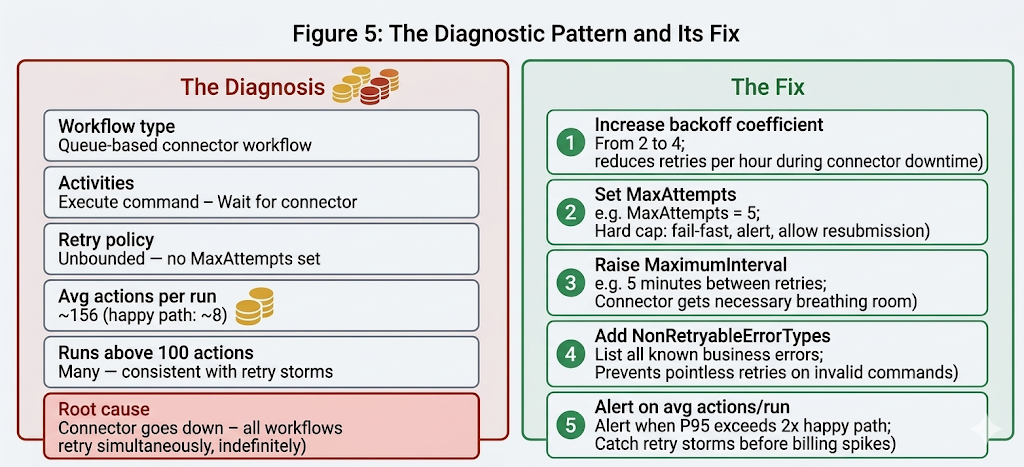
Figure 5: The diagnostic pattern and its fix. A connector workflow with unbounded retries shows an average of ~156 actions per run against a happy-path baseline of ~8. Five targeted configuration changes address the root cause without changing the business logic or the workflow’s fundamental reliability contract.
The fix in Figure 5 does not reduce the workflow’s reliability. It changes how the workflow behaves during sustained dependency outages: instead of retrying indefinitely and generating thousands of actions during the outage window, it retries with appropriate spacing, reaches a cap, fails clearly, and allows the operational process to handle resubmission. The workflow is more predictable, the cost is bounded, and the dependency has better recovery conditions.
The five changes shown — higher backoff coefficient, hard MaxAttempts, raised MaximumInterval, NonRetryableErrorTypes, and an alert on average actions per run — are each independent. They can be implemented incrementally, starting with the highest-impact change (backoff coefficient) and adding the others as the operational process for each is established.
How to Diagnose Retry-Related Cost in Your Own System
Before changing any retry policy, establish a baseline understanding of which workflow types are contributing most to retry-generated actions. The Temporal Cloud metrics dashboard and the workflow event history provide the necessary data.
- Identify workflow types where average actions per run significantly exceeds the happy-path action count. Happy-path action count is the number of actions a workflow generates when no retries occur — typically 4 to 6 per activity plus workflow start and completion events. A ratio of 3x or higher indicates meaningful retry activity.
- Look at the distribution of actions per run, not just the average. A workflow type with an average of 20 actions per run might have most runs at 6 to 8 actions with occasional runs at 100 to 200 during outage periods. The average understates the peak cost.
- Correlate spikes in action count with infrastructure incidents. If your action count spikes align with periods when a downstream dependency was experiencing issues, retry policy is the mechanism connecting the two.
- Check for business error types appearing in retry sequences. Open a few event histories for failed workflows and look at the error types in the activity failed events. If you see the same business error type repeated across multiple retry attempts, those errors belong in NonRetryableErrorTypes.
Production Readiness Checklist for Temporal Retry Policies
Before shipping retry-heavy Temporal workflows to production, confirm:
- Every activity has an explicit retry policy instead of relying only on defaults
- Backoff coefficients are tuned based on dependency behavior and outage duration
- Maximum retry intervals are long enough to avoid hammering recovering services
- MaxAttempts is set where cost must be bounded
- Fail-fast behavior is used for scheduled jobs, batch syncs, and workflows where a fresh run is cleaner than indefinite retry
Closing Thoughts
Temporal’s default retry policy is a sensible starting point for a prototype. It is not a sensible production policy for activities that call dependencies which experience real outages at scale. The default was designed to be correct in the general case, not to be cost-optimal under the specific conditions of production traffic with dependency instability.
The four strategies in this post — higher backoff coefficient, economic capping, tiered retry, and fail-fast — are not alternatives to each other. They are a toolkit. The right combination depends on the failure characteristics of each specific dependency and the operational process available for handling escalated failures. Applying them requires knowing which workflows are retry-cost-heavy, which errors are genuinely non-retryable, and which dependencies are the source of the instability.
The diagnostic signal — average actions per run significantly higher than the happy-path baseline — is visible in the Temporal Cloud metrics today. If that signal is present in your environment and the retry policies have not been explicitly tuned, the cost saving from addressing it is immediate and directly proportional to how much higher that ratio is.
Is your team still routing billing spike investigations through engineering?
If an action count spike during an incident requires an investigation to explain rather than a dashboard to read — that’s a retry policy and observability gap that compounds with every outage.
Frequently Asked Questions About Temporal Retry Policies
Why do Temporal retries increase cost?
Each Temporal activity retry generates additional billable actions, including scheduling, starting, and recording the failed attempt.
At production scale, retries across hundreds or thousands of workflows can turn a dependency outage into a major action-count and billing spike.
What is an unbounded retry policy in Temporal?
An unbounded retry policy keeps retrying without a strict maximum attempt limit until the activity eventually succeeds or the workflow is otherwise stopped.
This can be useful for some durable workflows, but it becomes risky when downstream outages last for minutes or hours and every retry adds cost.
How can teams reduce Temporal retry costs?
Teams can reduce retry costs by increasing backoff intervals, setting hard retry caps, classifying non-retryable errors, and using fail-fast patterns where appropriate.
The goal is not to remove retries, but to make retry behavior match the failure pattern and business value of each activity.
What errors should not be retried in Temporal?
Business validation errors such as invalid input, missing records, duplicate entities, permission failures, and insufficient funds usually should not be retried.
These should be added to NonRetryableErrorTypes so Temporal does not waste actions retrying failures that will deterministically fail again.
Xgrid offers two entry points depending on where you are:
- Temporal 90-Day Production Health Check — we audit your retry policies, identify which workflow types have unbounded or misconfigured retries, correlate action spikes with dependency incidents, and give you a prioritized fix list with projected monthly savings per workflow type.
- Temporal Reliability Partner — for teams that want a named Temporal expert embedded long-term to review retry policy decisions for new activities before they go live and prevent cost surprises before they reach the billing dashboard.
Both are fixed-scope. No open-ended retainer required to get started.
Related Temporal Production Guides
- For broader production architecture decisions, read: Temporal Workflow Production Readiness: 6 Architecture Decisions
- For retry visibility, stuck workflows, Search Attributes, and action-count monitoring, read: Temporal Observability in Production Guide
- For activity timeouts, heartbeats, and long-running workflow recovery, read: Long-Running Temporal Workflows in Production
- For idempotency, failover readiness, and high-availability workflow design, read: Temporal Workflow Best Practices for High Availability
Related Articles



Related Articles
Established in 2012, Xgrid has a history of delivering a wide range of intelligent and secure cloud infrastructure, user interface and user experience solutions. Our strength lies in our team and its ability to deliver end-to-end solutions using cutting edge technologies.
NAVIGATE
Cloud & DevOps Web & Mobile Apps Temporal Digital Marketing GTM Engineering Marketo Consulting HubSpot Consulting Company Careers ResourcesOFFICE ADDRESS
US Address:
Plug and Play Tech Center, 440 N Wolfe Rd, Sunnyvale, CA 94085
Dubai Address:
Dubai Silicon Oasis, DDP, Building A1, Dubai, United Arab Emirates
Pakistan Address:
Xgrid Solutions (Private) Limited, Bldg 96, GCC-11, Civic Center, Gulberg Greens, Islamabad
Xgrid Solutions (Pvt) Ltd, Daftarkhwan (One), Building #254/1, Sector G, Phase 5, DHA, Lahore
Xgrid © 2026. All rights reserved.