Temporal + OpenAI Agents SDK Sandbox: What It Means for Production AI Workflows



For the past two years, AI agents have dominated engineering roadmaps — autonomous systems designed to plan, execute tool calls, manage state, and complete complex multi-step tasks with minimal human intervention. The architecture has been compelling on paper: give a model memory, tools, and an objective, and let it run.
But anyone who has pushed an agent past a proof-of-concept knows where the story usually goes. Timeouts. Partial failures mid-task. State lost on a worker crash. No clean way to resume. The gap between a working demo and a production-grade system has been one of the most frustrating open problems in applied AI engineering.
On April 16, 2026, that gap got a lot narrower.
OpenAI shipped a landmark update to its Agents SDK — introducing native sandbox execution — giving agents their own isolated, controlled environments to read files, run code, and execute shell commands without touching production infrastructure. Simultaneously, Temporal extended the SDK with durable, fault-tolerant workflow infrastructure, solving the one problem sandboxing alone cannot: what happens to your agent’s state when something goes wrong mid-task.
At Xgrid, as a Certified Temporal Cloud Partner, we have seen firsthand how enterprises struggle to move agentic systems beyond simple chat interfaces. This announcement changes that by offering a standardized, secure, and—most importantly—durable environment for agents to work.
What Is the OpenAI Agents SDK Sandbox Update?
- 1. Native Sandbox Execution
Agents can now run inside controlled, isolated computer environments — workspaces where they can read and write files, install dependencies, execute shell commands, and run code — without ever touching the broader system. Think of it as giving your agent its own walled-off room to work in, rather than letting it roam freely through your production infrastructure.
Developers can bring their own sandbox setup or choose from built-in support for providers including Modal, Daytona, E2B, Blaxel, Cloudflare, Runloop, and Vercel. A new Manifest abstraction also makes workspaces portable — the same agent configuration can move from a local prototype environment to production cloud storage on AWS S3, Google Cloud Storage, Azure Blob Storage, or Cloudflare R2 without rewriting anything.
- 2. A More Capable Model-Native Harness
The updated harness is built specifically around how frontier models like OpenAI’s latest perform best. It now includes configurable memory for persisting context across long-running tasks, sandbox-aware orchestration for coordinating multi-step work, and Codex-style filesystem tools. It also standardises common agentic primitives: tool use via MCP, custom instructions via AGENTS.md, code execution via a shell tool, and file edits via apply_patch.
As OpenAI’s product team put it, the launch is fundamentally about making the SDK compatible with all major sandbox providers so developers can “go build these long-horizon agents using our harness and with whatever infrastructure they have.”
The initial release is Python-first, with TypeScript support planned for a future release.
Why Sandboxing Matters for Enterprise AI Agents
This isn’t just a developer convenience feature — sandboxing solves one of the most serious structural problems in deploying AI agents at enterprise scale: security and blast radius.
When an AI agent has unrestricted access to a system, a single bad output — whether from a hallucination, an injected prompt, or a misconfigured tool — can cascade into a serious incident. The new architecture addresses this directly by separating the control harness from the compute layer. Credentials and API keys live entirely outside the sandboxed environment where model-generated code actually runs. An injected malicious command cannot reach the central control plane or steal primary keys, protecting the wider corporate network from lateral movement.
Beyond security, sandboxing also solves a cost and reliability problem. Long-running agent tasks — compiling a financial report, processing a document pipeline, running an automated code review — frequently fail midway due to network timeouts, container crashes, or API rate limits. Under the old architecture, losing the sandbox meant losing the entire run. Under the new architecture, losing the sandbox container does not mean losing the operational run. State is preserved. Work is not wasted.
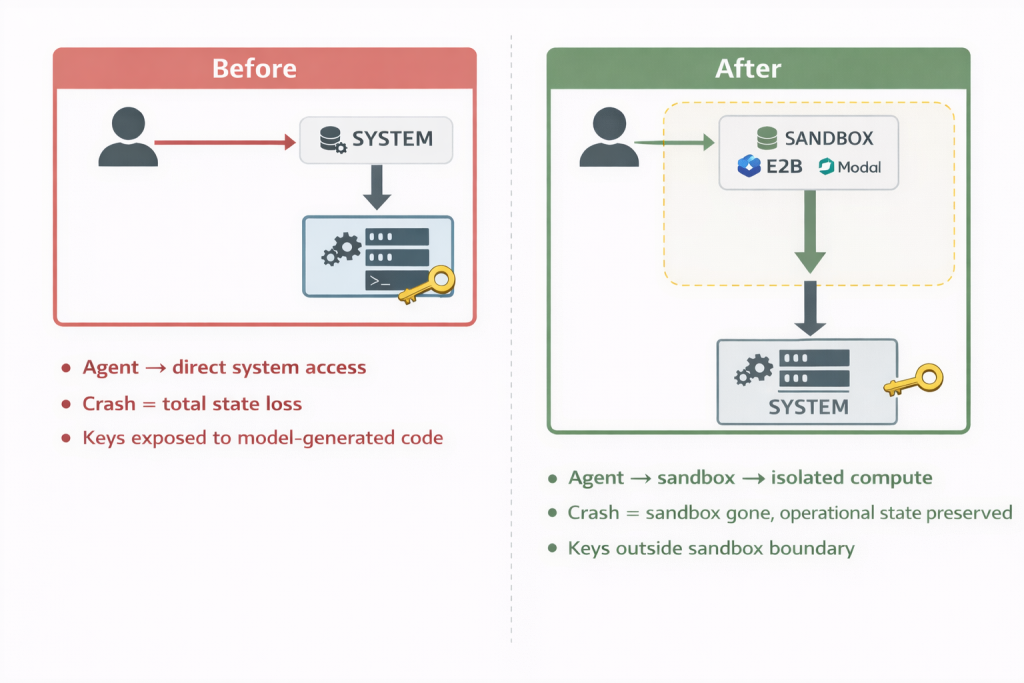
Enter Temporal: Making Sandbox Agents Durable
OpenAI’s sandbox support solves the isolation problem. Temporal’s integration solves the durability problem. Without it, developers face three major infrastructure hurdles:
- 1. State Loss:If a host process crashes during a 30-minute task, the sandbox, the conversation history, and the entire work product are lost, forcing the user to start over.
- 2. Resource Waste:Many agents spend most of their time waiting for human feedback. If a sandbox sits idle while consuming compute resources, costs skyrocket as you scale to hundreds or thousands of sessions.
- 3. Operational Rigidity:In a standard environment, you cannot easily move an agent’s work from a local Docker container to a cloud-hosted environment mid-task.
Temporal solves all three problems. By running agents as Temporal Workflows, the agent’s state is persisted automatically. It can survive server restarts and consume zero compute resources while waiting for input.
BUILDING PRODUCTION AI AGENTS WITH TEMPORAL?Sandboxed execution helps, but reliable AI agents still need durable state, retry-safe tool calls, resumable sessions, and clear observability. Xgrid’s Temporal practice helps teams design agent workflows that survive timeouts, worker crashes, human wait states, and infrastructure changes before brittle state management or unsafe tool execution blocks scale. |
Inside the Architecture: Turning Agents into “Invincible” Applications
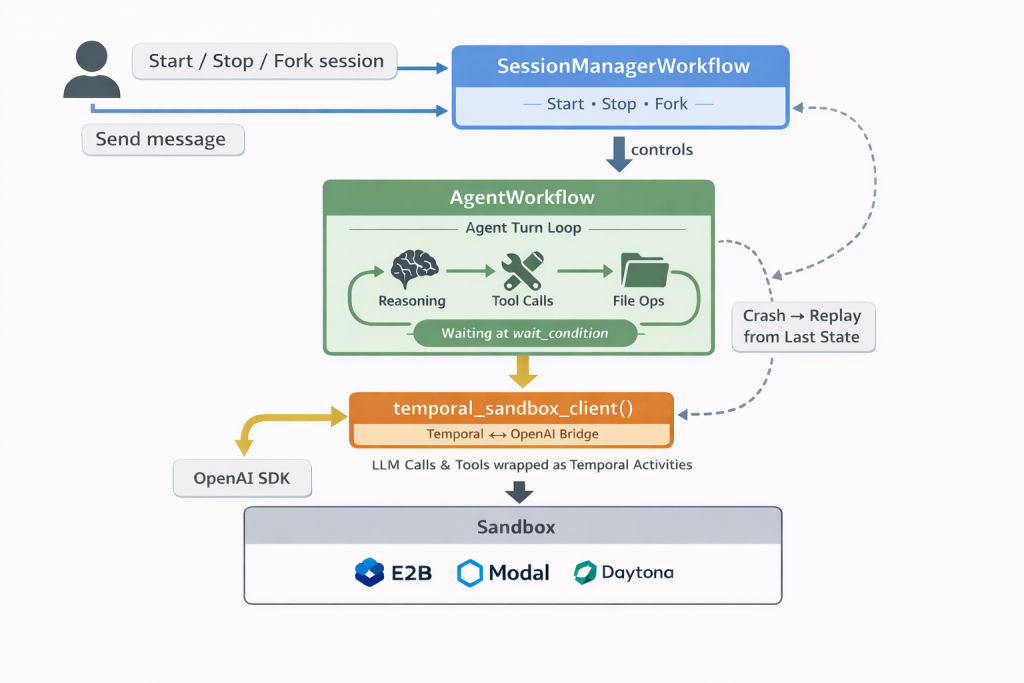
The integration between Temporal and the OpenAI Agents SDK is built on a tripartite architecture designed for resilience and scale.
1. The AgentWorkflow
This is a long-lived Temporal workflow that wraps the OpenAI SandboxAgent. It handles the “agent turn”—the loop of reasoning, tool calls, and file operations. The “magic” happens at the workflow.wait_condition, where the workflow idles without consuming compute until a new message arrives. If a worker process crashes mid-turn, Temporal simply replays the workflow and resumes from the exact last state, ensuring context is never lost.
2. The SessionManagerWorkflow
Instead of building a traditional database-backed server to track agent sessions, this component uses Temporal’s own workflow abstractions. It allows for durable tracking of all agent sessions, enabling operations like starting, stopping, renaming, and even forking sessions.
3. The temporal_sandbox_client() Bridge
The technical “seam” that ties these worlds together is a single function: temporal_sandbox_client(). This bridge wraps the OpenAI sandbox client, ensuring that every operation—from LLM API calls to shell commands—is executed as a Temporal Activity. This makes every action retryable and fault-tolerant without requiring the developer to change how they write their agent logic.
That architecture matters because these reliability problems do not just show up in polished demos — they appear in messy, high-stakes operating environments. Xgrid has seen firsthand how durable execution changes what is possible when systems have to keep running despite failures, delays, and unstable conditions.
Production readiness checklist for sandboxed AI agents with Temporal
Before shipping sandboxed AI agent workflows to production, confirm:
- Agent state is persisted through Temporal workflows, not only in the sandbox process
- LLM calls, shell commands, file edits, and tool calls run as retryable activities
- Long waits for user input do not keep sandbox compute running unnecessarily
- Session start, stop, rename, fork, and resume behavior is modeled explicitly
- Logs, Event History, and workflow state expose enough context to debug failed agent turns
What This Unlocks for the OpenAI Space
This partnership doesn’t just improve reliability; it unlocks entirely new capabilities for developers building on OpenAI:
- Seamless Backend Switching: A developer can start an agent in a local Docker environment and then switch mid-conversation to a cloud provider like Daytona. The workspace files are carried over via portable snapshots, and the durability remains intact throughout the transition.
- Session Forking: This is a first-class operation where a source workflow is paused, and a new workflow is started with the identical conversation history. This allows users to test two different approaches in parallel from the same starting point.
- Zero-Cost Idling: Because the workflow persists on the Temporal server rather than in a running process, organizations can scale to thousands of concurrent sessions without paying for idle sandboxes.
The Bigger Picture: AI Infrastructure Is the Next Competitive Frontier
There’s a broader signal in this release worth paying attention to. The race in AI is no longer just about which model is smartest — it’s about which infrastructure can make agents reliable, safe, and auditable enough to deploy at scale.
Temporal explicitly framed this release as part of becoming “the durability layer for the entire agent ecosystem.” OpenAI is positioning its SDK as “the definitive infrastructure layer for enterprise agent development.” The major cloud providers are racing to offer their own sandbox environments. What’s emerging is a new stack for enterprise AI — one where the boring, essential parts of reliability, state management, and fault tolerance are becoming just as important as model quality.
For engineering leaders, this means the architectural decisions being made right now — how agents are orchestrated, how state is managed, how execution is isolated — will define the ceiling of what your AI systems can actually do in production. Getting them right early matters.
Frequently asked questions about Temporal and OpenAI Agents SDK sandbox workflows
What does the OpenAI Agents SDK sandbox help with?
The OpenAI Agents SDK sandbox gives AI agents an isolated environment to read files, run code, execute commands, and perform tool work safely.
This reduces the blast radius of model-generated actions by separating agent execution from sensitive production infrastructure.
Why use Temporal with sandboxed AI agents?
Temporal adds durable execution to sandboxed agent workflows so state can survive crashes, timeouts, long waits, and worker restarts.
This helps agents resume from the last known state instead of losing progress when a sandbox or host process fails.
How does Temporal reduce idle compute cost for AI agents?
Temporal workflows can wait durably for user input or external events without keeping an active sandbox container running.
That makes it easier to support many long-running agent sessions without paying for compute while they are idle.
What production risks remain for sandboxed AI agents?
Sandboxing improves isolation, but teams still need retry-safe tool calls, idempotent side effects, observability, workflow versioning, and secure credential handling.
Temporal helps with durable orchestration, but the agent architecture still needs clear boundaries between reasoning, execution, state, and external systems.
Why Xgrid is the Right Partner for Your AI Transformation
Xgrid is an official Temporal partner.
What does that mean in practice? It means our engineering teams have deep, hands-on expertise with Temporal’s durable execution model — not just surface-level familiarity, but the kind of knowledge that comes from actually building production systems on it. And it means when Temporal ships something as significant as this — a co-engineered extension with OpenAI that lands in the official OpenAI repository — our customers can act on it quickly and confidently, with a partner who already knows the terrain.
We specialize in solving the exact classes of challenges this new SDK addresses:
- Workflow Reliability: We design systems that survive failures, retries, and worker restarts in real-world production conditions.
- State Management at Scale: We architect workflows that manage complex states across long-running executions without hitting Temporal limits.
- Security and Compliance: For industries like healthcare or finance, we implement HIPAA-compliant payload encryption and robust audit trails.
- Infrastructure Scaling: We design worker autoscaling and queue architectures to ensure your system remains responsive even during traffic spikes.
Whether you are looking to migrate legacy orchestration layers or ship your first production-grade AI agent, Xgrid has the expertise to get you there without rewrites or downtime.
Ready to move your agents from prototype to production?
Book a Free Temporal Consultation with Xgrid today. Let us help you review your current workflows and build a plan to achieve 99.99% reliability faster.
Related Temporal and agentic AI guides
- For the broader multi-agent orchestration problem, read: Agentic AI Orchestration with Temporal: Solving Multi-Agent System Challenges
- For moving agentic AI systems from demos to reliable production workflows, read: Agentic AI with Temporal: From Prototypes to Production
- For long-running agent memory, timeouts, and crash recovery, read: Why Long-Running AI Agents Crash — Fix with Temporal
- For common Temporal-based AI agent failure modes, read: Temporal AI Agent Orchestration: 11 Production Failure Patterns
Related Articles



Related Articles
Established in 2012, Xgrid has a history of delivering a wide range of intelligent and secure cloud infrastructure, user interface and user experience solutions. Our strength lies in our team and its ability to deliver end-to-end solutions using cutting edge technologies.
NAVIGATE
Cloud & DevOps Web & Mobile Apps Temporal Digital Marketing GTM Engineering Marketo Consulting HubSpot Consulting Company Careers ResourcesOFFICE ADDRESS
US Address:
Plug and Play Tech Center, 440 N Wolfe Rd, Sunnyvale, CA 94085
Dubai Address:
Dubai Silicon Oasis, DDP, Building A1, Dubai, United Arab Emirates
Pakistan Address:
Xgrid Solutions (Private) Limited, Bldg 96, GCC-11, Civic Center, Gulberg Greens, Islamabad
Xgrid Solutions (Pvt) Ltd, Daftarkhwan (One), Building #254/1, Sector G, Phase 5, DHA, Lahore
Xgrid © 2026. All rights reserved.