Don’t Rewrite Your Domain: How to Migrate Long-Running Processes to Temporal Safely



There is a dangerous misconception that adopting Temporal requires you to rethink your entire application architecture.
Engineering leaders look at their legacy systems—5-year-old billing scripts, nightly reconciliation jobs, complex provisioning pipelines—and assume that moving them to a durable execution platform means rewriting them from scratch.
They imagine “modeling workflows” means ripping apart the domain logic that has been generating revenue for years.
This stops migration before it starts.
The truth is: You do not need to re-model your domain to get the benefits of durable execution.
In fact, the safest migrations treat domain logic as a “black box.” We don’t rewrite the code that does the work; we simply change the engine that drives it.
Here is the architectural pattern (The Wrapper) we use to migrate long-running processes to Temporal without touching a single line of your core business logic.
The Architecture: Decoupling “Doing” from “Driving”
To migrate without re-modeling, we must distinguish between two types of logic currently mixed in your scripts:
- 1. Domain Logic (The “Doing”):The code that calculates a fee, generates a PDF, or updates a SQL row.This is valuable, battle-tested, and should not be touched.
- 2. Orchestration Logic (The “Driving”):The while loops, sleep() statements, retry counters, and error catching.This is fragile and should be replaced.
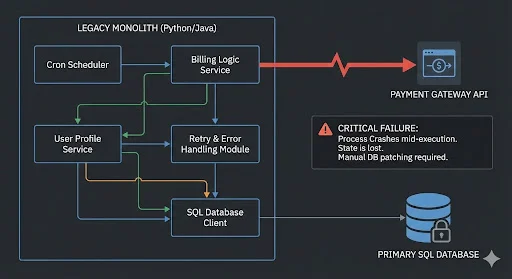
In your current scripts, these are tangled together, creating a single point of failure.
The Strategy: The Wrapper Pattern
We treat your existing service methods or scripts as immutable assets. We wrap them in Temporal primitives to give them superpowers (retries, timeouts, visibility) without opening the box.
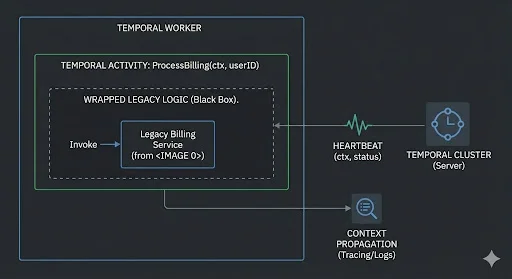
Step 1: The Activity Wrapper (Keep the Logic)
Let’s say you have a legacy method ProcessMonthlyBilling(userId). It’s 500 lines of complex Python or Go. It works.
Do not refactor it.
Instead, create a Temporal Activity that acts as a dumb pass-through. Crucially, we implement heartbeating to ensure that long-running legacy processes don’t time out.
// The Activity Wrapper
// It bridges the gap between the orchestration engine and your legacy code.
func (a *BillingActivities) ProcessBillingActivity(ctx context.Context, userID string) error {
// 1. Setup: Instantiate your existing, battle-tested service
legacyService := billing.NewLegacyService()
// 2. HEARTBEAT (Critical for Long-Running Processes)
// Since your legacy logic might run for 10+ minutes, we must
// tell Temporal we are still alive so it doesn’t timeout.
// This allows us to wrap very slow legacy processes safely.
go func() {
for {
select {
case <-ctx.Done():
return
case <-time.After(30 * time.Second):
activity.RecordHeartbeat(ctx, “Legacy process still running…”)
}
}
}()
// 3. Execution: Call the EXACT same method you use today.
// We are not re-modeling the billing logic. We are just running it.
return legacyService.ProcessMonthlyBilling(userID)
}
The Win: You haven’t introduced bugs into the billing logic because you haven’t touched the billing logic.
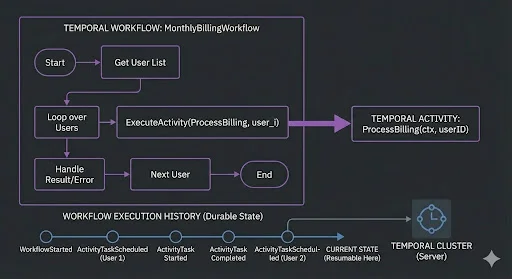
Step 2: The Workflow Orchestrator (Replace the Script)
Currently, your “orchestration” might be a cron script that iterates through a list of users. If that script crashes on User #4,000, you lose your place.
We replace that loop with a Temporal Workflow, which manages the state and orchestration, calling the wrapped activity we just created.
// Define the “Policy” – How do we handle legacy instability?
options := workflow.ActivityOptions{
StartToCloseTimeout: time.Minute * 30, // Allow time for legacy slowness
RetryPolicy: &temporal.RetryPolicy{
InitialInterval: time.Second,
MaximumAttempts: 3,
// Crucial: Don’t retry logic errors, only transient infrastructure errors
NonRetryableErrorTypes: []string{“DomainLogicError”, “InvalidUser”},
},
}
ctx = workflow.WithActivityOptions(ctx, options)for _, userID := range userIDs {
// Execute the wrapper activity.
// Temporal automatically persists the cursor state of ‘i’.
// If the worker crashes here, it resumes right here.
err := workflow.ExecuteActivity(ctx, a.ProcessBillingActivity, userID).Get(ctx, nil)if err != nil {
// Log failure but continue to next user (Saga pattern)
logger.Error(“Billing failed for user”, “id”, userID)
}
}
return nil
}
The Operational Upgrade:
The logic inside ProcessMonthlyBilling is exactly the same. But now, if the server crashes, the Workflow resumes execution at the exact user it left off on. You have gained durability without re-modeling your data or your domain.
The Technical Safety Net: Idempotency
There is one rule for this pattern: Idempotency.
Temporal guarantees that your Activity will run at least once. In rare network failure scenarios, it might try to run your wrapper twice.
- Ideal: Your legacy ProcessMonthlyBilling checks if already_billed: return.
- Wrapper Fix: If you cannot touch the legacy code, put the check in the wrapper:
// 1. Instantiate existing legacy service
legacyService := billing.NewService()
// 2. Call the legacy method directly
err := legacyService.ProcessMonthlyBilling(userID)
// 3. The “Wrapper” Logic: Interpret the error, don’t prevent it.
if err != nil {
// If the legacy system throws a “Duplicate Entry” or “Already Paid” error,
// we treat that as a SUCCESS in Temporal (idempotency achieved).
if IsDuplicateTransactionError(err) {
return nil // Swallow the error, return success
}
// Real failures (DB down, Network timeout) should still bubble up
// so Temporal can retry them.
return err
}
return nil
}
MIGRATING LEGACY WORKFLOWS WITHOUT A REWRITE?The safest Temporal migrations start by separating the domain logic that does the work from the fragile orchestration that drives it. Xgrid’s Temporal practice helps teams identify a beachhead workflow, wrap existing scripts or service methods as Activities, and replace brittle cron jobs, retry loops, and manual recovery with durable execution. |
This ensures that even if you don’t re-model the domain, you protect it from side effects.
Why This Pattern Wins for Platform Teams
- 1. Risk Reduction:You are not rewriting business logic. You are wrapping it. The regression risk is near zero.
- 2. Immediate Visibility:You instantly get a Temporal UI showing exactly which step every process is in. No more log-diving to find “where the script died.”
- 3. Speed:We see teams ship their first migrated workflow in days, not months, because they bypass the architectural debates that stall greenfield projects.
Start Your Beachhead Migration
Migration isn’t about rewriting your stack. It’s about securing the execution path.
At Xgrid, our Forward-Deployed Engineers use this exact Wrapper Pattern to help teams move their first critical workflow—from “cron chaos” to Temporal predictability—without re-modeling their domain.
Migration readiness checklist for the Temporal Wrapper Pattern
Before wrapping a legacy process with Temporal, confirm:
- Core domain logic stays unchanged and is called through a thin Activity wrapper
- The old script’s loops, sleeps, retries, and error handling move into the Workflow
- Wrapped Activities heartbeat when legacy steps can run for several minutes
- Duplicate or already-completed legacy outcomes are treated safely through idempotency checks
- The first migration candidate is high-value but bounded enough to ship as a beachhead workflow
Frequently asked questions about migrating legacy workflows to Temporal
Do you have to rewrite domain logic to migrate to Temporal?
No. A safe Temporal migration can preserve existing domain logic and only replace the orchestration layer around it.
The Wrapper Pattern keeps battle-tested business code intact while Temporal handles retries, timeouts, progress tracking, and recovery.
What is the Temporal Wrapper Pattern?
The Temporal Wrapper Pattern wraps existing scripts or service methods inside Temporal Activities.
A Temporal Workflow then drives those Activities, replacing fragile loops, cron jobs, sleeps, retry counters, and manual recovery logic.
Why is idempotency important when wrapping legacy code?
Temporal Activities may retry after crashes, timeouts, or network failures, so wrapped legacy steps must be safe to run more than once.
If the legacy code cannot be changed, the wrapper should detect duplicate or already-completed outcomes and return success where appropriate.
What is a good first workflow to migrate to Temporal?
A good first migration candidate is a long-running process with clear steps, recurring failures, manual recovery pain, and limited domain complexity.
Examples include billing runs, reconciliation jobs, provisioning pipelines, batch processing, or approval workflows that already work but are operationally fragile.
Ready to wrap and migrate your first workflow?
We offer a structured Beachhead Workflow Sprint to identify your best migration candidate, wrap it, and ship it to production in weeks.
Book a 15-Minute Migration Planning Call
Related Temporal migration and production guides
- For long-running workflow failure modes like heartbeats, Continue-As-New, replay safety, and signal handling, read: Long-Running Temporal Workflows in Production
- For go-live checks across retries, timeouts, determinism, payloads, scaling, and observability, read: Temporal Workflow Production Readiness: 6 Architecture Decisions
- For a practical recovery example using durable workflow steps and idempotent activities, read: How Xgrid Used Temporal to Recover Long-Running Jobs Automatically
- For workflow visibility, Search Attributes, stuck executions, and production debugging, read: Temporal Observability in Production Guide
Related Articles



Related Articles
Established in 2012, Xgrid has a history of delivering a wide range of intelligent and secure cloud infrastructure, user interface and user experience solutions. Our strength lies in our team and its ability to deliver end-to-end solutions using cutting edge technologies.
NAVIGATE
Cloud & DevOps Web & Mobile Apps Temporal Digital Marketing GTM Engineering Marketo Consulting HubSpot Consulting Company Careers ResourcesOFFICE ADDRESS
US Address:
Plug and Play Tech Center, 440 N Wolfe Rd, Sunnyvale, CA 94085
Dubai Address:
Dubai Silicon Oasis, DDP, Building A1, Dubai, United Arab Emirates
Pakistan Address:
Xgrid Solutions (Private) Limited, Bldg 96, GCC-11, Civic Center, Gulberg Greens, Islamabad
Xgrid Solutions (Pvt) Ltd, Daftarkhwan (One), Building #254/1, Sector G, Phase 5, DHA, Lahore
Xgrid © 2026. All rights reserved.