How Xgrid Used Temporal to Recover Long-Running Jobs Automatically (No Manual Intervention)



For one of Xgrid’s enterprise customers, long-running jobs had become difficult to operate reliably.
These workflows were central to the platform. They handled multi-step business processes, called external services, updated databases, and sometimes ran long enough that even minor infrastructure issues could interrupt them. The real challenge was not just failure itself. It was a recovery.
When a job failed halfway through, the team had to determine what had already completed, what still needed to run, and whether retrying might duplicate side effects. That made recovery slow, operationally expensive, and risky.
Xgrid’s task was to eliminate that uncertainty.
The solution was not to add more scripts, more retry cron jobs, or more operational runbooks. Instead, Xgrid changed the execution model itself by using Temporal to turn long-running jobs into durable workflows that could recover automatically.
The Core Problem: Long-Running Jobs Without Reliable Recovery
The customer did not have a broken platform. They had a platform with workflows that had outgrown the recovery model around them.
Long-running jobs exposed a familiar set of weaknesses:
- failure handling depended too much on application code and manual operator judgment
- execution state was hard to reason about once a workflow was interrupted
- retry behavior was inconsistent across different steps
- observability into workflow progress was limited
- a single failure could turn into a manual investigation
The key issue was that execution and recovery were too loosely defined. The system could run the jobs, but it did not have a durable, built-in way to preserve progress and resume cleanly when something went wrong.
That is the kind of problem Temporal is designed to solve.
How Xgrid Used Temporal to Redesign Long-Running Job Recovery
Xgrid started by isolating one of the customer’s most important long-running workflows and redesigning it around a simple principle:
Every critical business process should be represented as a durable workflow, not as a fragile process running on a single worker.
Instead of treating the job as one large block of execution, Xgrid broke it into clearly defined steps and mapped those steps into Temporal primitives.
At a high level, the architecture looked like this:
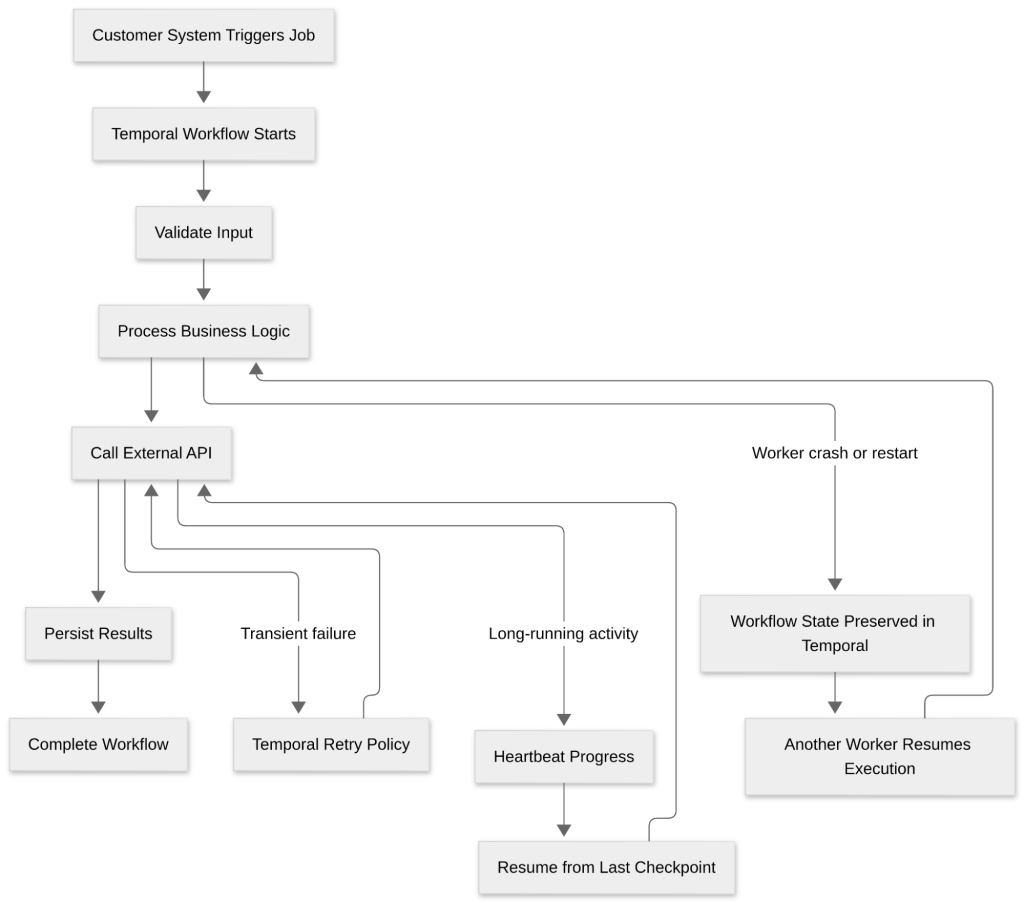
This shift changed everything. Once the workflow itself became durable, recovery no longer depended on a human reconstructing state from logs and database records.
Step 1: Break Long-Running Jobs into Durable Workflow Steps
The first design decision was to stop modeling the customer’s long-running job as one opaque process.
Xgrid decomposed the workflow into smaller, well-defined units such as:
- input validation
- business rule execution
- third-party API calls
- data transformation
- database updates
- finalization and completion handling
This matters because recovery only becomes precise when the system knows where one step ends and the next begins.
In a monolithic job, a failure leaves too many unanswered questions. In a step-based workflow, the orchestration engine knows exactly which steps completed successfully and which step failed. That makes resumption deterministic instead of guesswork.
Step 2: Use Temporal workflows for orchestration, not side effects
Xgrid used Temporal workflows as the control plane for execution.
The workflow was responsible for:
- sequencing steps
- tracking progress
- deciding what happens next
- handling retries
- waiting for timers or external signals
- preserving state across restarts and failures
The actual side effects were moved into activities.
Activities handled the real work, such as calling APIs, reading or writing data, or interacting with downstream systems. This separation is important because orchestration and side effects have different reliability concerns.
The workflow keeps the state machine durable. Activities do the work that might fail, time out, or need to be retried.
That distinction let Xgrid build a system where the customer’s business process remained recoverable even when the underlying workers or dependencies were not perfectly reliable.
Step 3: Make Activities Idempotent for Safe Retries
Once retries become automatic, idempotency becomes mandatory.
Xgrid treated this as a design rule. Any activity that could be retried had to be safe to run more than once, or at minimum be able to detect whether it had already been applied.
This was especially important for steps like:
- writing records to a database
- submitting requests to third-party APIs
- updating downstream state
- triggering follow-up operations
Without idempotency, automatic retries can create duplication. With idempotency, retries become safe and predictable.
This is one of the most important parts of making long-running jobs self-recovering. Temporal gives you the retry mechanism, but the activity design is what makes that mechanism safe in production.
Step 4: Configure Step-Level Retries in Temporal
Before the redesign, retry behavior often lived inside scattered application code or human decision-making.
Xgrid moved that logic into Temporal’s activity retry policies.
That meant each step could have explicit rules for:
- maximum retry attempts
- backoff intervals
- timeout thresholds
- failure classification
This allowed transient issues to recover automatically without restarting the entire workflow.
For example, if a third-party API call failed because of a temporary timeout, Temporal could retry just that activity. The workflow did not need to restart from the beginning, and the operator did not need to intervene.
That is a major difference between traditional job processing and workflow orchestration. A job system often retries the whole job. A workflow engine can retry the exact failing step while preserving the progress that already exists.
Step 5: Preserve Progress with Temporal Durable Execution
One of the biggest reasons Xgrid chose Temporal was its durable execution model.
In a traditional setup, a worker crash can leave execution in an ambiguous state. The process disappears, but the business workflow may be half complete. The team then has to inspect logs and infer what happened.
Temporal changes that by persisting workflow history and state. The workflow does not live only in memory on one machine. Its execution history is stored durably, so if a worker crashes or a deployment interrupts processing, another worker can continue from the recorded state.
From the customer’s point of view, the workflow resumes instead of restarting.
That made manual recovery unnecessary in many cases because the system no longer forgot where it was.
Step 6: Use Activity Heartbeats for Long-Running Operations
Some of the customer’s work was long-running even within a single step.
For those cases, Xgrid used activity heartbeats to report progress periodically. This allowed Temporal to retain checkpoint-like information during execution.
If an activity was interrupted after making substantial progress, the next attempt did not have to start from the very beginning. It could resume from the most recent known checkpoint.
This is especially useful for expensive operations such as large data processing or lengthy external interactions. Instead of losing forty minutes of progress because a worker restarted, the system can resume closer to where it left off.
That is one of the practical ways Xgrid reduced wasted work and made failure recovery feel automatic rather than disruptive.
Step 7: Model Waiting and Delays in Temporal Workflows
Long-running jobs are not always actively computing. Often they are waiting.
They may wait for:
- an external callback
- a downstream service result
- an approval event
- a scheduled retry window
- a timer-based delay
Xgrid modeled these pauses directly in Temporal instead of outsourcing them to separate cron jobs, state tables, or polling loops.
This made waiting durable. The workflow could pause without consuming unnecessary compute and then resume when the right event arrived.
That is a subtle but important improvement. Systems often become fragile not during active execution, but during the periods between steps. By making waiting a first-class workflow behavior, Xgrid removed another source of hidden failure.
Step 8: Improve Workflow Observability and Failure Visibility
Automatic recovery only builds trust if the team can see what the system is doing.
So Xgrid did not stop at orchestration. It also improved visibility into workflow behavior by instrumenting the workflow lifecycle and exposing execution history more clearly.
That gave the customer better answers to questions like:
- which step is this workflow currently on
- what failed and why
- how many times was this activity retried
- how long is each step taking
- where are bottlenecks forming
This changed operational behavior in an important way. Engineers no longer had to reconstruct workflow state from several disconnected sources. They could inspect the workflow directly and understand both current progress and prior failure behavior.
That is critical when moving from manual recovery to confidence in automated recovery.
Step 9: Manage Long-Running Workflow History at Scale
For very long-lived processes, workflow history can grow over time.
Xgrid accounted for that by designing workflows so they could be continued cleanly when necessary, carrying forward business state while resetting execution history boundaries. This kept workflows maintainable and performant even as they ran for extended periods or handled repeated cycles of work.
This is one of those details that matters in real systems. Self-healing is not only about retries. It is also about making sure the workflow remains healthy and operable over time.
Results: Automatic Recovery for Long-Running Jobs with Temporal
Once the workflow was restructured around Temporal, recovery became a property of the system rather than an operator workflow.
Before, a failed long-running job typically required:
- inspecting logs
- checking which side effects had already happened
- deciding whether retrying was safe
- manually restarting execution
- monitoring closely to avoid duplicate work
After the redesign, the flow looked very different:
- the workflow persisted its state durably
- failed activities retried automatically according to policy
- completed steps did not have to be rerun
- interrupted long-running work could resume from heartbeat progress
- operators could inspect workflow history directly instead of reconstructing it manually
That is the real meaning of “recovered without manual intervention.” It does not mean failures disappeared. It means the recovery path became built into the system.
Why Temporal Enabled Reliable Long-Running Job Recovery
The most important thing Xgrid changed was not a tool. It was the boundary between business logic and operational recovery.
Instead of embedding recovery in scattered scripts and human decisions, Xgrid embedded it in the workflow model itself.
That worked because the design combined several ideas that reinforce each other:
- durable workflow state
- step-level retries
- idempotent activities
- checkpoint-style heartbeats
- explicit timeouts
- durable waiting
- clear execution visibility
None of these ideas alone is enough. Together, they create a system where long-running jobs can fail, recover, and continue without turning into incidents.
Final Thoughts: Building Self-Recovering Long-Running Workflows with Temporal
Many long-running jobs fail not because the business logic is wrong, but because the recovery model is weak.
That was the challenge Xgrid solved for this customer. The platform already did important work. What it needed was a better way to preserve progress, isolate failures, and resume execution automatically.
By redesigning the workflow with Temporal, Xgrid made long-running jobs durable, observable, and self-recovering. Instead of relying on manual intervention to recover from interruptions, the customer gained a system that could keep moving on its own.
And that is the real value of workflow orchestration done well: not just running jobs, but making sure they survive the kinds of failures real systems inevitably face.
Related Articles



Related Articles
Established in 2012, Xgrid has a history of delivering a wide range of intelligent and secure cloud infrastructure, user interface and user experience solutions. Our strength lies in our team and its ability to deliver end-to-end solutions using cutting edge technologies.
NAVIGATE
Cloud & DevOps Web & Mobile Apps Temporal Digital Marketing GTM Engineering Marketo Consulting HubSpot Consulting Company Careers ResourcesOFFICE ADDRESS
US Address:
Plug and Play Tech Center, 440 N Wolfe Rd, Sunnyvale, CA 94085
Dubai Address:
Dubai Silicon Oasis, DDP, Building A1, Dubai, United Arab Emirates
Pakistan Address:
Xgrid Solutions (Private) Limited, Bldg 96, GCC-11, Civic Center, Gulberg Greens, Islamabad
Xgrid Solutions (Pvt) Ltd, Daftarkhwan (One), Building #254/1, Sector G, Phase 5, DHA, Lahore
Xgrid © 2026. All rights reserved.