Durable Execution in Distributed Systems: How to Build Workflows on Temporal That Never Break



In the world of distributed systems, the “Happy Path” is a fairy tale. In reality, networks partition, downstream APIs timeout, and Kubernetes pods are evicted at the worst possible moments. Traditionally, developers have fought these demons with a “Reliability Tax”: thousands of lines of code dedicated to retry logic, state machines, polling loops, and complex database management just to ensure a process finishes what it started.
But what if your code was “immortal”? What if a process could crash, the server could lose power, and upon rebooting, the code picked up exactly on the line it left off, with all its local variables intact?
This is the promise of Durable Execution, and Temporal is the engine that makes it a reality.
The Architecture of Durability
Most systems are “stateless”. If a process dies, the state dies with it. Temporal flips this by using Event Sourcing to decouple the execution from the underlying hardware.
When you run a workflow on Temporal, it isn’t just “running”—it is being recorded. Every time your code performs a side effect (like calling an external API), that result is persisted in the Temporal Cluster. If the worker executing your code vanishes, another worker picks up the Event History, replays the logic, and resumes execution without the rest of the system even noticing there was a failure.
The Building Blocks of an Unbreakable Workflow
To build workflows that never break, you must understand the three core components of the Temporal programming model:
1. Workflows (The Orchestrator)
A Workflow is a piece of code written in a standard language (Go, Java, Python, TypeScript) that defines your business logic. The key requirement here is Determinism. Because Temporal “replays” this code to recover state, it must produce the same output every time it runs.
- Don’t: Use UUID.random() or DateTime.now() inside a workflow.
- Do: Use Temporal’s built-in, deterministic wrappers for time and randomness.
2. Activities (The Workers)
Activities are where the “real world” happens. This is where you call your Stripe API, update your SQL database, or send an email. Unlike Workflows, Activities do not need to be deterministic. Temporal handles the complexity of retrying these activities based on your custom policies. You can tell an Activity to retry for 5 minutes or 5 days—Temporal handles the persistence of that timer automatically.
3. The Temporal Cluster
This is the backend service (the “Brain”) that maintains the state. It manages the task queues and ensures that even if your entire fleet of workers goes down, the state of your business processes remains safely tucked away in a database until the workers return.
Why This Changes Everything
When you embrace Durable Execution, you gain access to superpowers that were previously massive engineering undertakings:
- Durable Timers: Instead of setting up a Cron job or a Redis-backed scheduler, you simply write workflow.sleep(“30 days”). The worker doesn’t sit idle for a month; the state persists, and the workflow is “woken up” 30 days later.
- Signals and Queries: You can interact with a running workflow. If a user needs to cancel a subscription mid-process, you send a Signal. If you want to know the current status of a multi-day onboarding process, you send a Query.
- Automatic Error Handling: In a traditional system, a “500 Internal Server Error” from a dependency often triggers a manual cleanup. In Temporal, that error simply triggers the retry policy. The workflow stays in a “Running” state until the dependency is back up.
A Sneak Peak into Temporal Super Powers
To truly appreciate Temporal’s power in a distributed system, you have to look at the “Intermittent Failure” scenario. In a standard microservices setup, if Service A calls Service B and Service B is down, Service A has to handle the logic for retries, exponential backoff, and state persistence.
In Temporal, you write the “Happy Path,” and the system handles the chaos.
The Reliability Gap: Standard vs. Temporal
Imagine a Money Transfer system where you must deduct from one service and deposit into another.
| Feature | Standard Distributed System | Temporal (Durable Execution) |
|---|---|---|
| Network Timeout | You must write a retry loop and handle “zombie” requests. | Temporal automatically retries the Activity until it succeeds. |
| Server Crash | The state is lost. You need a recovery script to find unfinished jobs. | The Workflow is “immortal.” It resumes on a new worker automatically. |
| Long Delays | Requires a database, a polling service, and a scheduler. | A simple workflow.sleep() handles it with zero overhead. |
The Chaos Example: The Unreliable Bank API
Let’s look at a snippet where we transfer money. We will simulate a bank API that is notoriously flaky.
from datetime import timedelta
from temporalio import workflow
from temporalio.common import RetryPolicy
with workflow.unsafe.imports_passed_through():
from activities import withdraw, deposit
@workflow.def
class MoneyTransferWorkflow:
@workflow.run
async def run(self, source_account: str, target_account: str, amount: int) -> str:
# Define a policy: Retry every 10 seconds, up to 100 times if needed.
# This keeps the workflow “alive” even if the bank is down for hours.
retry_policy = RetryPolicy(
initial_interval=timedelta(seconds=10),
maximum_attempts=100
)
# Step 1: Withdraw (Durable side effect)
await workflow.execute_activity(withdraw, {“account”: source_account, “amount”: amount}, start_to_close_timeout=timedelta(minutes=1), retry_policy=retry_policy)
# Step 2: Deposit
# If the worker crashes here, Temporal knows Step 1 is DONE
# and will only resume from Step 2.
await workflow.execute_activity(deposit, {“account”: target_account, “amount”: amount}, start_to_close_timeout=timedelta(minutes=1), retry_policy=retry_policy)
return “Transfer Complete”
Why This is a Power Move:
- 1. Orphaned States: In a normal system, if Step 1 succeeds but the server dies before Step 2, you have a “lost” $100. In Temporal, the Workflow is a Single Source of Truth. It must reach Step 2 eventually.
- 2. Human in the Loop: If the deposit activity fails 100 times because the account is locked, the workflow will simply pause. A developer can fix the account, and then tell Temporal to “Retry.” The workflow continues as if nothing happened.
- 3. Observability: You can open the Temporal Web UI and see exactly which line of code is currently executing and how many times it has retried.
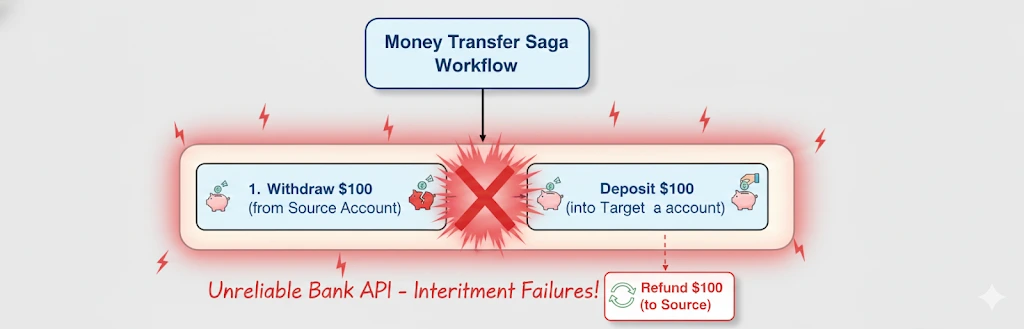
The Saga Pattern: “Undo” for Distributed Systems
In a distributed world, you can’t always “rollback” a database transaction across different microservices. If you successfully withdraw money but the deposit fails permanently (e.g., the account was closed), you need a Compensating Transaction to put the money back.
A Saga manages failures by executing a sequence of “compensating” activities when something goes wrong. In Temporal, this is incredibly clean because you can use a standard try/except block.
from datetime import timedelta
from temporalio import workflow
from temporalio.exceptions import ActivityErrorwith workflow.unsafe.imports_passed_through():
from activities import withdraw, deposit, refund_withdrawal@workflow.def
class MoneyTransferSaga:
@workflow.run
async def run(self, source: str, target: str, amount: int) -> str:
# We keep track of successful steps to “undo” them if needed
compensations = [] try:
# Step 1: Withdraw
await workflow.execute_activity(
withdraw,
{“account”: source, “amount”: amount},
start_to_close_timeout=timedelta(seconds=10),
) # Record that we need to refund if later steps fail
compensations.append(“refund_withdrawal”) # Step 2: Deposit
# We simulate a “Permanent Failure” (e.g., target account doesn’t exist)
await workflow.execute_activity(
deposit,
{“account”: target, “amount”: amount},
start_to_close_timeout=timedelta(seconds=10),
) return “Transfer Successful” except Exception as e:
# The “Saga” logic: If ANY step failed, run compensations in reverse
workflow.logger.error(f”Transfer failed: {str(e)}. Starting compensations…”) for comp in reversed(compensations):
if comp == “refund_withdrawal”:
# We run the refund as a new activity to ensure it’s durable
await workflow.execute_activity(
refund_withdrawal,
{“account”: source, “amount”: amount},
start_to_close_timeout=timedelta(seconds=10),
) raise e # Or return a “Clean Failure” message
Why This is Better Than Traditional Sagas
- 1. Implicit State: In other systems, you have to save the “Saga state” to a database at every step. In Temporal, the compensations list is just a local Python variable. Temporal handles the persistence of that list automatically.
- 2. Guaranteed Compensation: If the worker crashes during the compensation (the refund), Temporal ensures the refund is retried until it succeeds. You won’t end up in an inconsistent state where money is gone from both accounts.
- 3. Readability: The code reads like a standard business process, even though it’s managing complex distributed failure modes.
The power of the Saga pattern in Temporal lies in its guaranteed completion. In a traditional microservices architecture, a failure during a “compensation” (the refund) is a nightmare scenario that usually requires manual database intervention. In Temporal, the compensation is itself an Activity—meaning it will be retried with the same durability as the original action.
By using Sagas, you stop treating distributed failures as “system errors” and start treating them as “business flows.” You gain the ability to maintain eventual consistency across dozens of services without ever needing to manage a distributed lock or a complex state machine manually.
Best Practices for the Real World
- 1. Idempotency is Non-Negotiable: Because Activities can be retried, ensure that calling your “Charge Credit Card” activity twice doesn’t charge the customer twice. Use idempotency keys provided by your APIs.
- 2. Lean Workflows, Heavy Activities: Keep your Workflow logic purely for orchestration. Put all your heavy computation and external integrations into Activities.
- 3. Versioning: Since workflows can run for months, your code will change. Use Temporal’s versioning API to ensure that “Replays” use the version of the code that originally started the workflow.
Conclusion
The traditional approach to distributed systems is built on a foundation of anxiety: What if the server dies? What if the API times out? What if the state gets corrupted? We spend 80% of our time building safety nets and only 20% building the actual product.
Durable Execution flips the script. By offloading state management and fault tolerance to Temporal, you shift your focus from defensive programming to pure business logic. You stop writing “What If” code and start writing “What Next” code.
When you build with Temporal, you aren’t just building a resilient system—you are building an immortal one. Infrastructure will fail, networks will partition, and pods will be evicted, but your workflows will simply keep moving forward, one event at a time.
Related Articles



Related Articles
Established in 2012, Xgrid has a history of delivering a wide range of intelligent and secure cloud infrastructure, user interface and user experience solutions. Our strength lies in our team and its ability to deliver end-to-end solutions using cutting edge technologies.
NAVIGATE
Cloud & DevOps Web & Mobile Apps Temporal Digital Marketing GTM Engineering Marketo Consulting HubSpot Consulting Company Careers ResourcesOFFICE ADDRESS
US Address:
Plug and Play Tech Center, 440 N Wolfe Rd, Sunnyvale, CA 94085
Dubai Address:
Dubai Silicon Oasis, DDP, Building A1, Dubai, United Arab Emirates
Pakistan Address:
Xgrid Solutions (Private) Limited, Bldg 96, GCC-11, Civic Center, Gulberg Greens, Islamabad
Xgrid Solutions (Pvt) Ltd, Daftarkhwan (One), Building #254/1, Sector G, Phase 5, DHA, Lahore
Xgrid © 2026. All rights reserved.