The Memory Problem: Why Long-Running AI Agents Crash in Production (and How Durable Execution Fixes It)



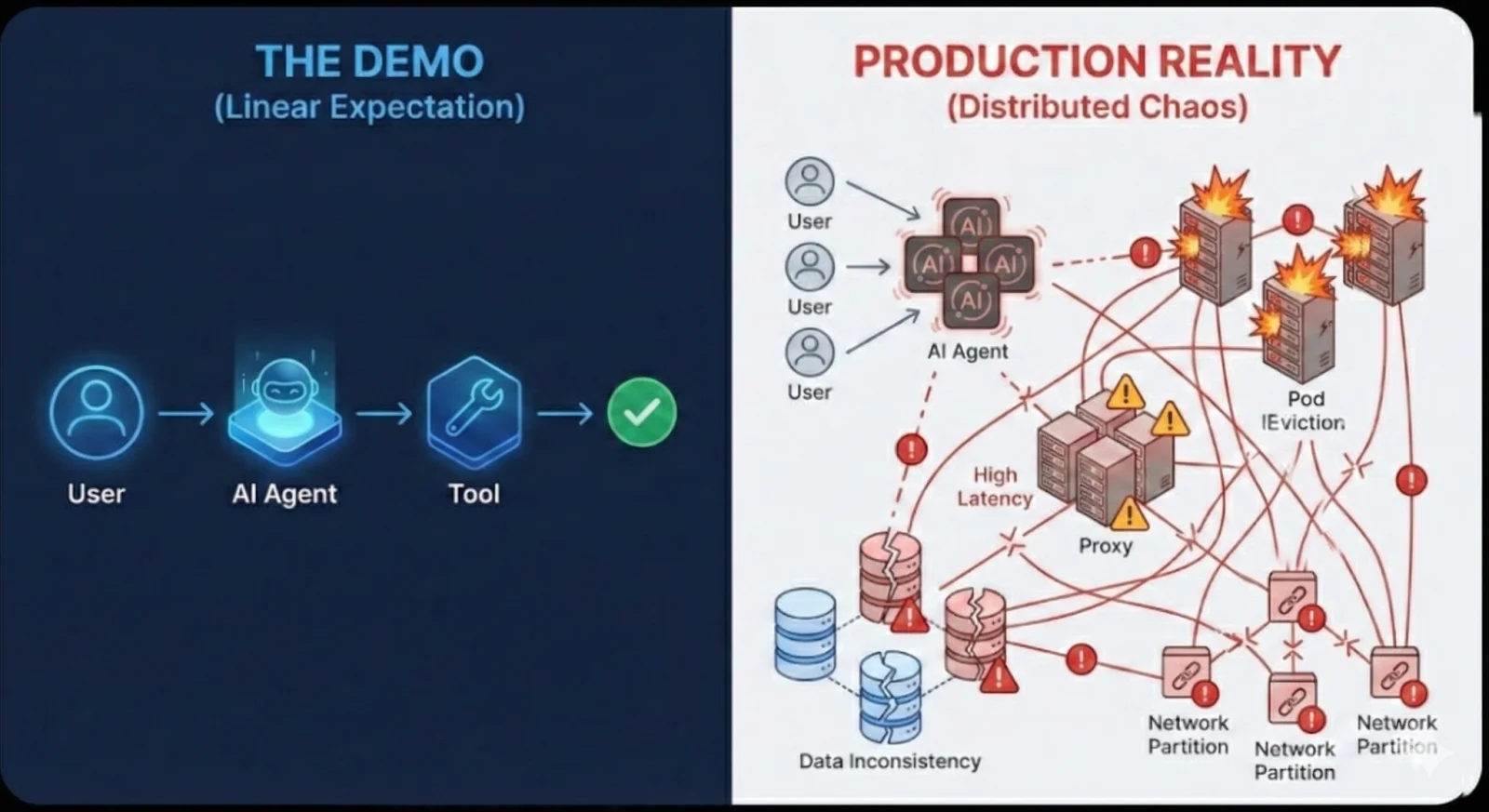
We have all seen the demos. An AI agent spins up, chains three tools together, scrapes a website, summarizes it, and posts to Slack. It takes 30 seconds. It looks magical.
Then you deploy it to production.
Suddenly, upstream rate limits or a hanging proxy rotation cause the scrape to stall for 45 seconds, hitting a hard timeout. The LLM hallucinates a tool argument that breaks your API client. The pod hosting the agent gets evicted during a deployment, and the agent’s in-memory context vanishes.
Or worse, the agent needs to wait 24 hours for a human approval on a sensitive action. You are forced to kill the process to save compute, leaving you with the complex engineering headache of rehydrating that state and resuming execution exactly where it left off the next day.
If you are building autonomous agents, you aren’t just building an LLM wrapper. You are building a distributed system. And distributed systems do not care about your prompt engineering; they care about state, failure boundaries, and time.
This is where standard orchestration fails, and where Temporal becomes the only viable architecture for production-grade agents.
The Core Conflict: Stochastic Intelligence vs. Deterministic Infrastructure
The fundamental problem with productionizing AI agents is the mismatch between the “Brain” and the “Body.”
- 1. The Brain (LLM): Is stochastic, slow, and non-deterministic. It outputs different things every time.
- 2. The Body (Infrastructure): Needs to be reliable, traceable, and deterministic.
Most teams try to shove both into a single Python loop using libraries like LangChain or AutoGen running on a standard web server. This works for a chatbot session that lasts 2 minutes. It fails catastrophically for a research agent that needs to run for 2 days.
Here is the deep architectural reality of how Temporal solves the three hardest problems in long-running agents: Non-Determinism, Durability, and The Human-in-the-Loop.
1. Solving the “Brain Freeze”: Handling Non-Determinism
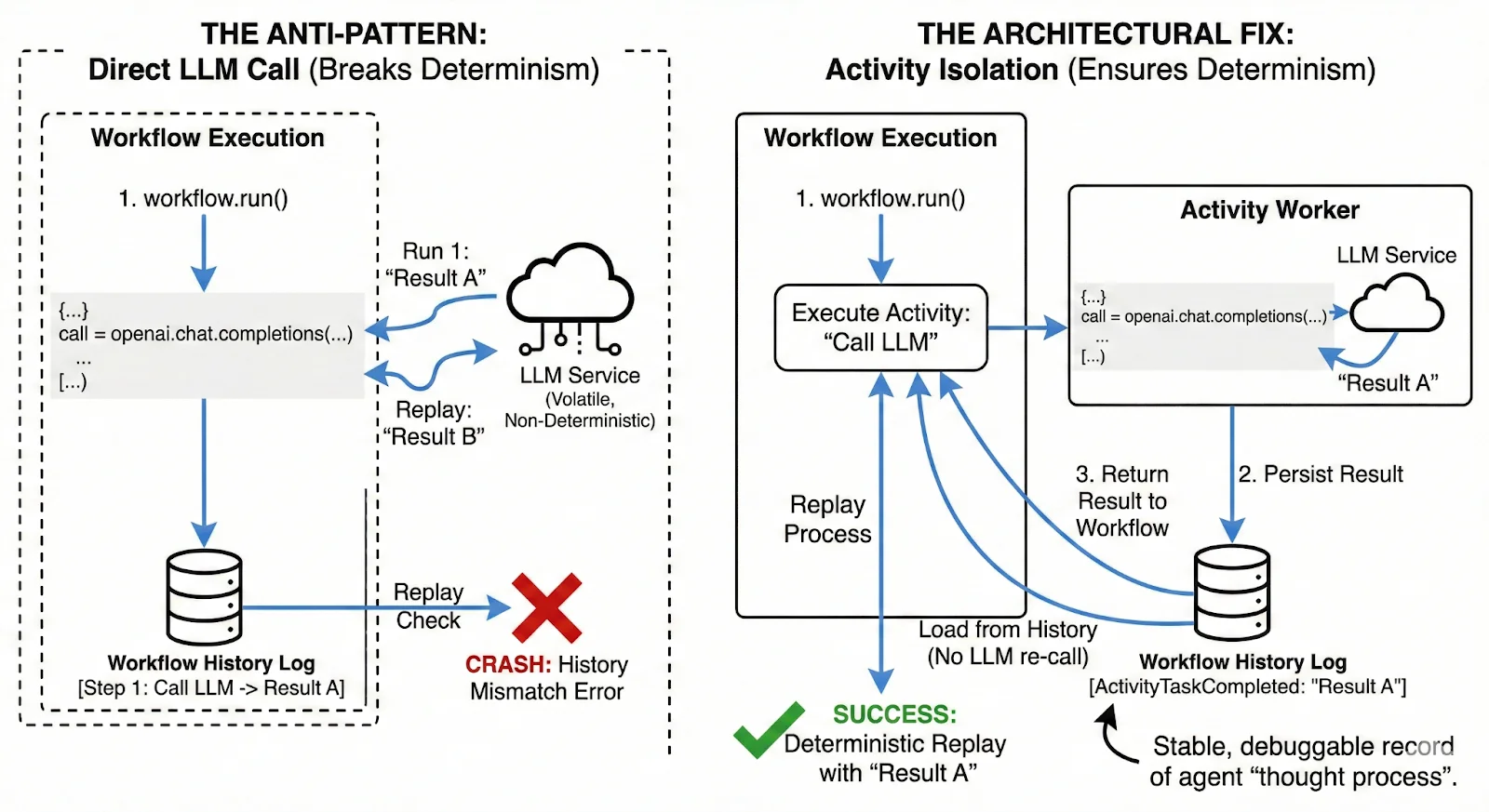
A core rule of Temporal is that Workflow code must be deterministic. If you replay the workflow history, the code must take the exact same path.
But LLMs are inherently non-deterministic. Even with temperature=0, floating-point non-determinism on GPUs can yield slight variations. If you call a non-deterministic operation directly inside a Temporal Workflow, you will break the Determinism Assumption. The workflow will crash on replay because the history won’t match the new execution.
The Architectural Fix:
You must treat the LLM as an external, volatile service.
- The Pattern: Isolate all LLM calls (reasoning steps) inside Activities.
- Why it works: Temporal persists the result of an Activity in the workflow history. When the workflow replays (e.g., after a crash or a sleep), it doesn’t re-call the LLM; it loads the static result from the history database.
This gives you a stable, replayable record of the agent’s “thought process.” You can debug exactly why an agent chose Tool A over Tool B three weeks ago, because that decision is frozen in the event history.
2. The “Black Box” Problem: Debugging Agents After They Fail
When an agent fails in production, the hardest part is rarely the failure itself. It is understanding why it behaved the way it did.
Most agent implementations rely on logs and metrics to reconstruct behavior after the fact. That approach breaks down for long-running agents that branch, retry, wait, and interact with multiple external systems over time. Logs are incomplete, reordered, or missing. In-memory state is gone. You are left guessing which reasoning step or tool call caused the failure.
For production agents, this lack of traceability is a serious risk. If an agent is allowed to touch infrastructure, money, or customer data, “we think it did X” is not an acceptable answer.
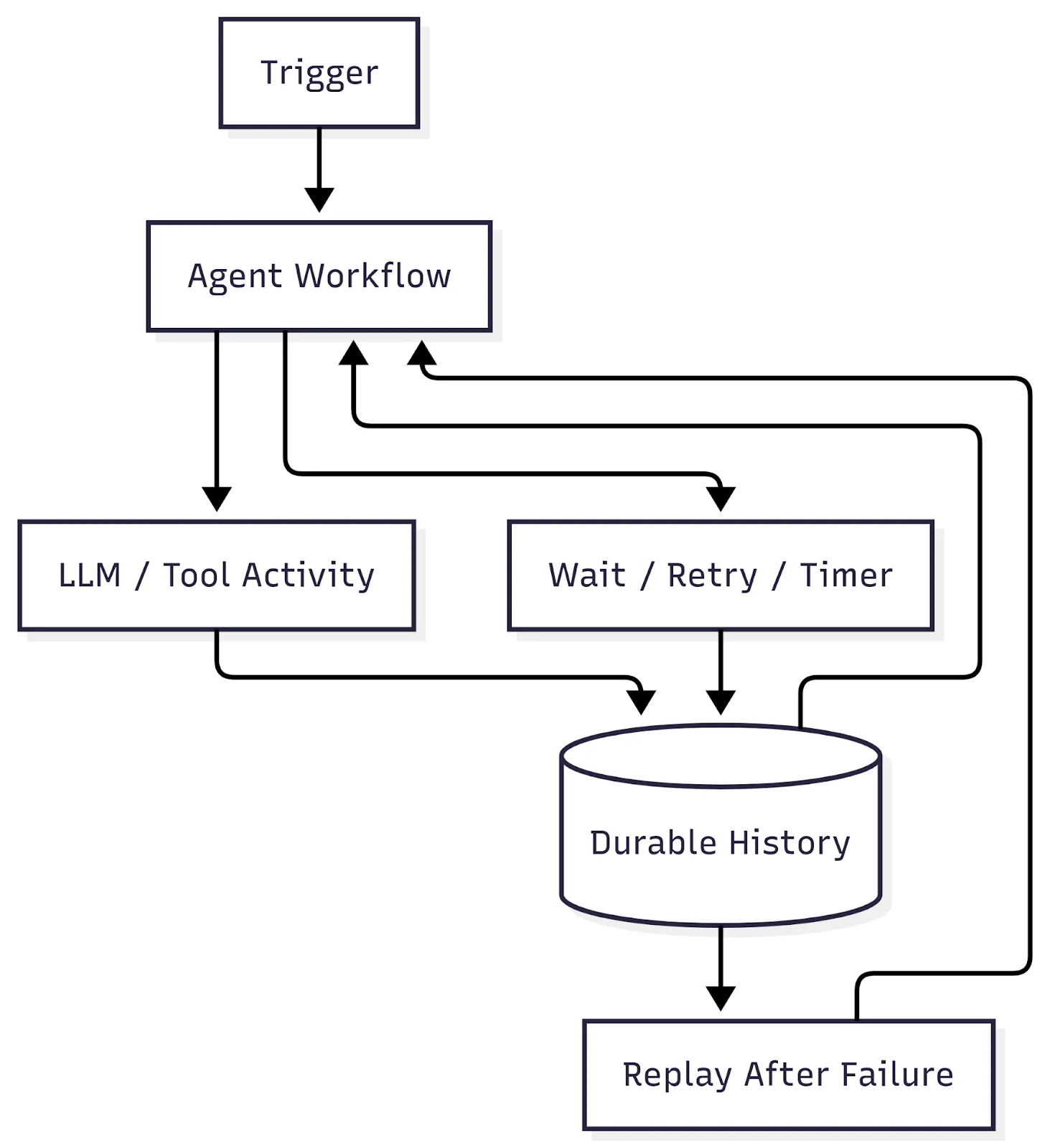
Temporal addresses this by making execution history a first-class artifact. A Workflow’s progress is captured as an ordered sequence of events that can be replayed deterministically. Instead of inferring behavior from logs, you can inspect exactly which steps ran, what data they produced, and where execution diverged or failed.
This shifts debugging from speculation to inspection. You can reason about retries, timeouts, and decision paths with certainty, even days or weeks later. For AI agents—where failures are often subtle and non-deterministic—this level of observability is what makes safe operation possible at scale.
3. The “Human-in-the-Loop” (HITL) Bottleneck
This is the feature every enterprise CTO asks for eventually: “The agent looks great, but it cannot authorize a payment over $500 without a human checking it first.”
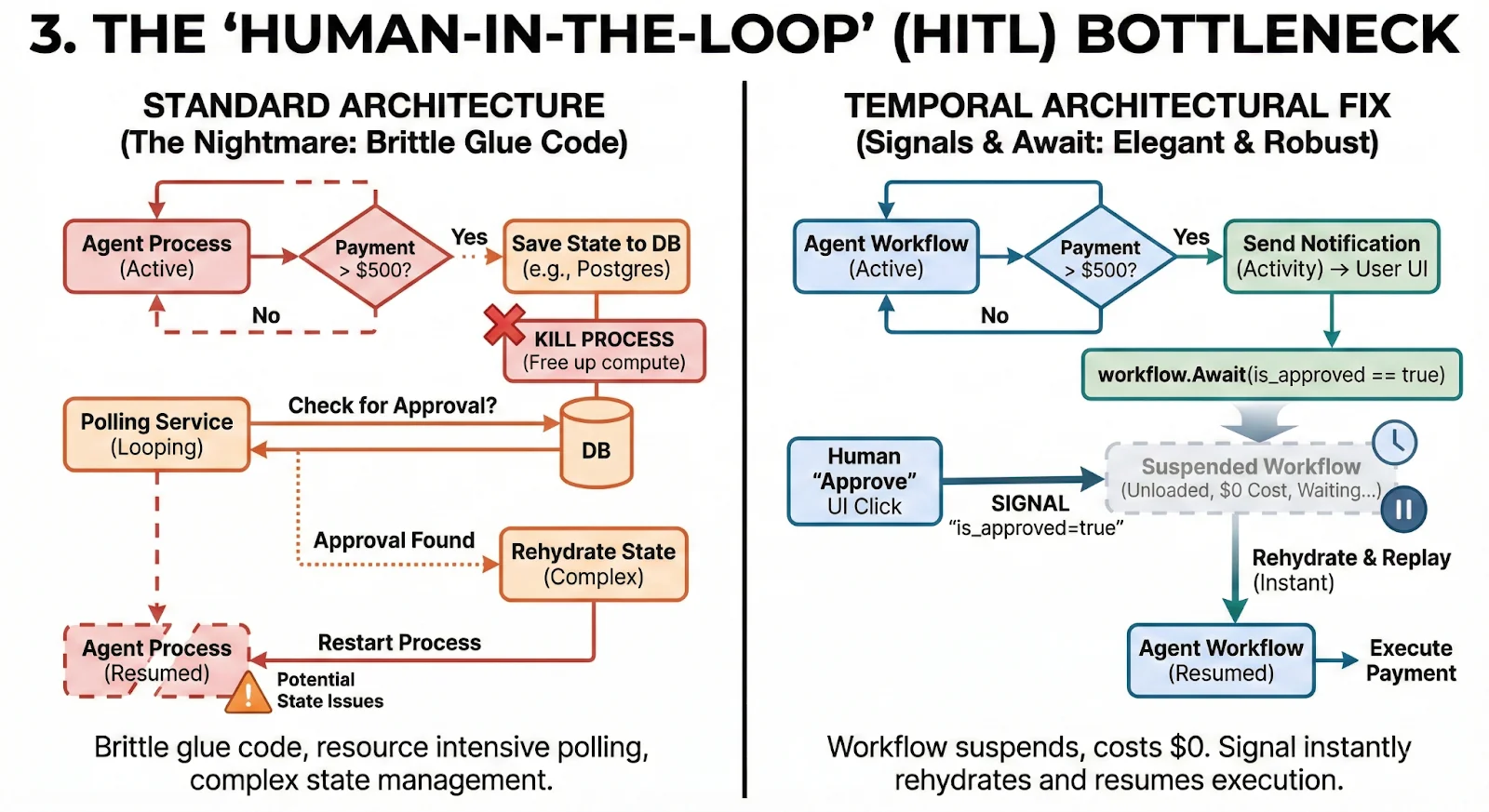
In a standard architecture, this is a nightmare. You have to save state to a DB, kill the process, build a polling service to check for approval, rehydrate the state, and resume. It is brittle glue code.
The Architectural Fix:
Use Temporal Signals and workflow.Await.
- The Pattern: The agent workflow reaches a sensitive step. It sends a notification (Activity) and then calls workflow. Await on a specific condition (e.g., is_approved == true).
- The Magic: The workflow suspends. It is unloaded from memory. It costs you $0 in computer resources while it waits. It can wait for an hour or a month.
- Resumption: When the human clicks “Approve” in your UI, your backend sends a Signal to the specific Workflow ID. Temporal immediately rehydrates the workflow state, replays up to the await point, and continues execution instantly.
Why “Good Enough” Scripting Isn’t Good Enough
You might be thinking, Can’t I just use a queue and a database for this?
You can. But you will end up reinventing a brittle, ad-hoc orchestration layer. To match what Temporal gives you out of the box, you would have to write, test, and maintain code to handle all of this:
- 1. Atomic State Persistence: You need to serialize the agent’s entire memory/context to a database after every single step. If you don’t use strictly ACID transactions with compare-and-swap logic, a race condition between a user “Stop” signal and an LLM “Tool Call” response will corrupt your agent’s state forever.
- 2. Durable Timers & Scheduling: If you need 500 agents to run market analysis every hour, a simple cron job will trigger a “thundering herd” that hits upstream rate limits instantly. You would need to build a distributed scheduler from scratch to handle jitter, catch-up logic, and overlap policies (e.g., “don’t start run #2 if run #1 is still going”). Temporal Schedules handle this complex orchestration natively.
- 3. Worker Liveness & Heartbeating: If the pod running your agent goes silent for 5 minutes, is it dead? Or just processing a really long 128k context prompt? You need to implement a heartbeat mechanism with lease management to detect dead workers versus slow ones—and reassign the work exactly once.
- 4. Distributed Rate Limiting: When you scale to 500 concurrent agents, you will hit upstream rate limits instantly—whether you are calling OpenAI, Anthropic, or a private model endpoint. Implementing a global, distributed token bucket rate limiter across multiple worker nodes (to handle 429s correctly without Redis race conditions) is a distributed systems project in itself.
- 5. Versioning Long-Running Flows: What happens when you change your prompt engineering logic while 5,000 agents are still running the old logic? You need to build a versioning system that allows old agents to drain on v1 code while new agents start on v2, or risk DeserializationErrors crashing your production fleet.
- 6. Idempotency & Fencing: If a worker crashes after executing that $500 transfer but before writing the success to the database, your retry logic will send the money again. You need to implement fencing tokens or rigorous deduping logic to prevent a double-spend scenario.
Temporal gives you these primitives out of the box. You write the business logic; it handles the plumbing.
The Production Reality: You Need a “Golden Pattern”
The gap between a working prototype and a production agent is usually the failure handling logic.
At Xgrid, we have solved multiple cases for customers, giving us valuable insight into these challenges and how to resolve them effectively.. Many businesses have the agent logic, but they don’t have the Execution Architecture. They are terrified of the “first workflow” going live because they don’t know how to handle the edge cases of long-running processes.
This is why we don’t just “consult.” We embed Forward-Deployed Engineers to ship that first foundational workflow with you. We implement the “Golden Pattern”—the standardized scaffolding for retries, signals, and observability—so your team can stop debugging race conditions and start shipping intelligence.
If you are staring at a prototype that works on your laptop but terrifies you in production, let’s fix the architecture.
Related Articles



Related Articles
Established in 2012, Xgrid has a history of delivering a wide range of intelligent and secure cloud infrastructure, user interface and user experience solutions. Our strength lies in our team and its ability to deliver end-to-end solutions using cutting edge technologies.
NAVIGATE
Cloud & DevOps Web & Mobile Apps Temporal Digital Marketing GTM Engineering Marketo Consulting HubSpot Consulting Company Careers ResourcesOFFICE ADDRESS
US Address:
Plug and Play Tech Center, 440 N Wolfe Rd, Sunnyvale, CA 94085
Dubai Address:
Dubai Silicon Oasis, DDP, Building A1, Dubai, United Arab Emirates
Pakistan Address:
Xgrid Solutions (Private) Limited, Bldg 96, GCC-11, Civic Center, Gulberg Greens, Islamabad
Xgrid Solutions (Pvt) Ltd, Daftarkhwan (One), Building #254/1, Sector G, Phase 5, DHA, Lahore
Xgrid © 2026. All rights reserved.